Author’s articles

May 27, 2026
Cutting Elasticsearch DiskBBQ query quantization time by 5x
See how asymmetric quantization cuts DiskBBQ query quantization overhead from about 20% to 4% with little recall impact.
May 6, 2026
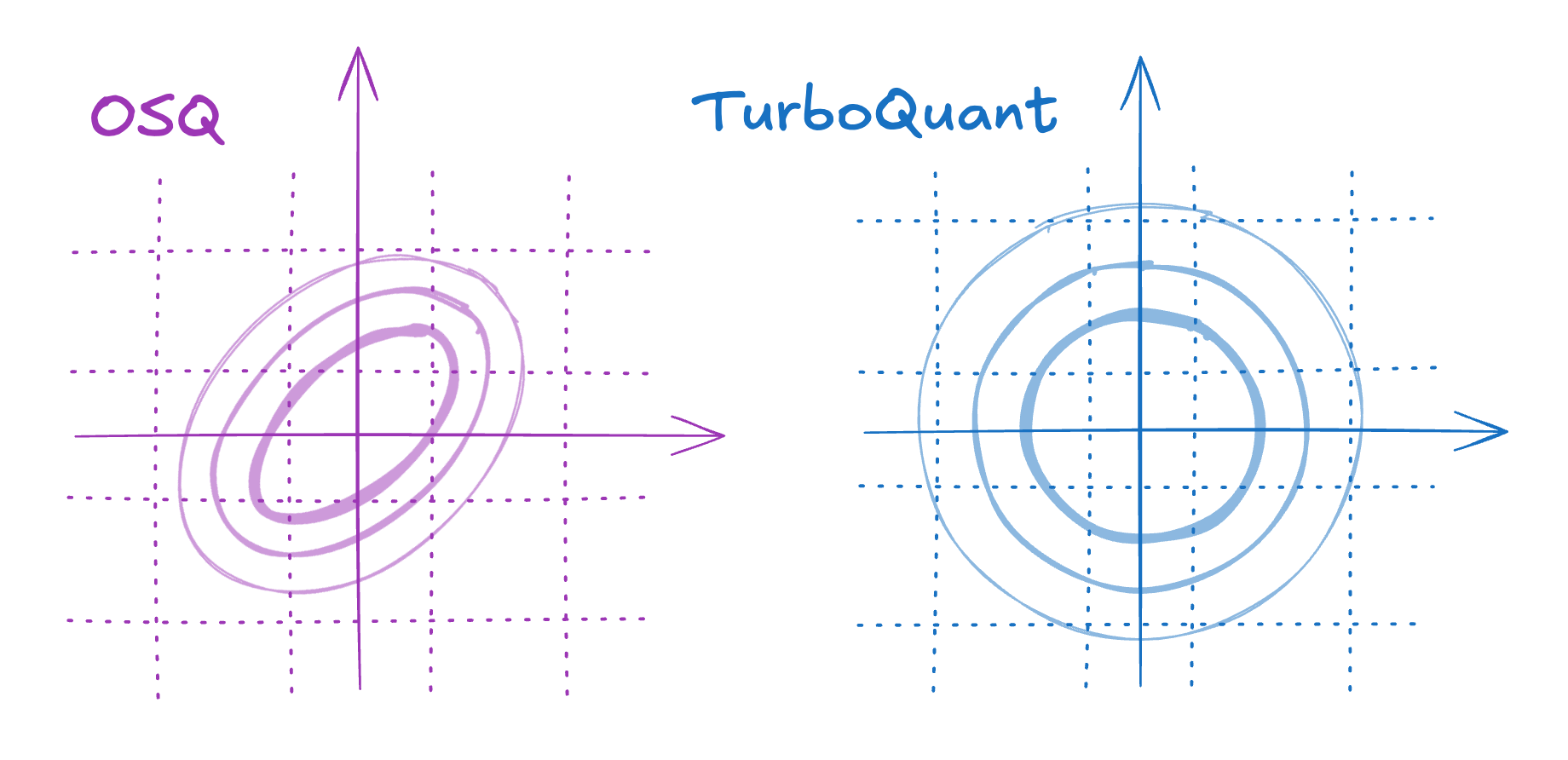
Elasticsearch's BBQ vs. TurboQuant: 10–40× faster on CPU and lower ranking noise
A head-to-head look at Elasticsearch BBQ and TurboQuant, including throughput, ranking accuracy, and why uniform quantization wins for CPU vector search with up to 40× faster comparisons and smaller ranking noise.
April 17, 2026
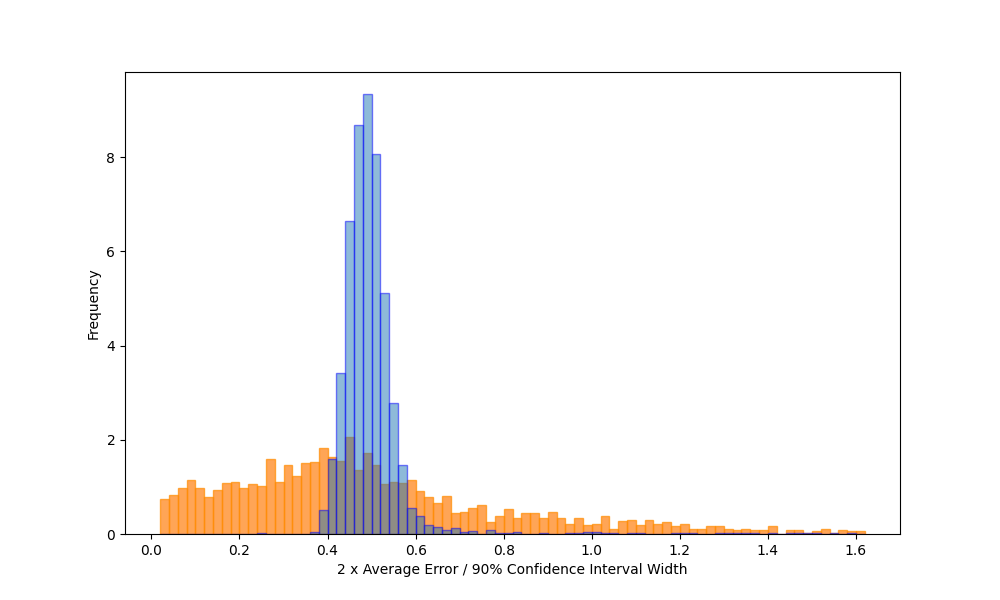
Fast approximate Elasticsearch ES|QL - part II
Explaining the approach we use to obtain fast approximate Elasticsearch ES|QL queries and the testing we did of error estimation.
April 16, 2026
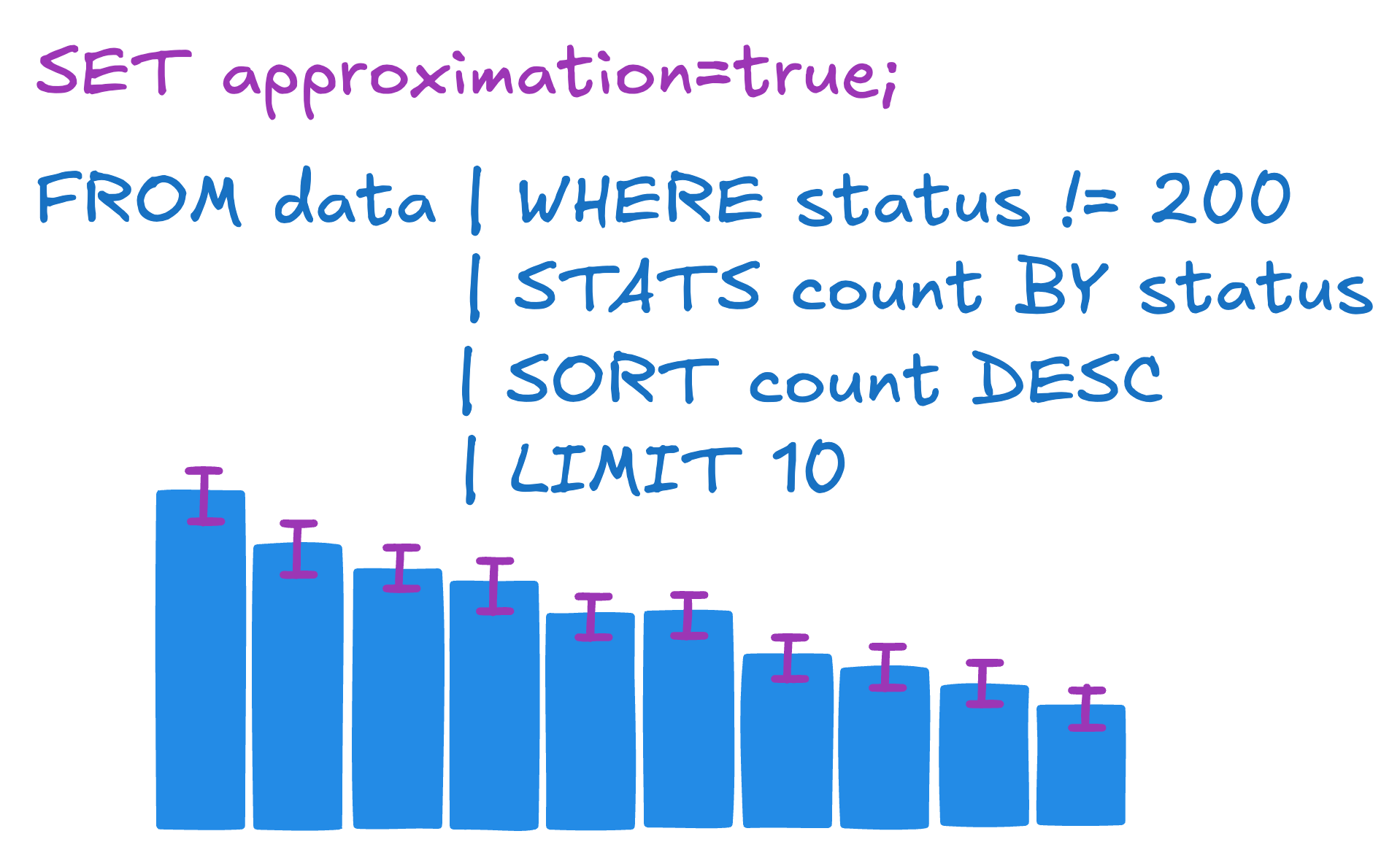
Fast approximate Elasticsearch ES|QL - part I
Introducing the work we've done on a fast approximate querying mode for Elasticsearch ES|QL. In many cases, it allows us to achieve orders of magnitude latency reductions while providing accurate estimates.
May 31, 2025
Optimizing scalar quantization with sparse preconditioners
We discuss a sparse preconditioner to apply to vectors which results in more stable quantization performance with respect to data distribution.

April 7, 2025
Speeding up merging of HNSW graphs
Explore the work we’ve been doing to reduce the overhead of building multiple HNSW graphs, particularly reducing the cost of merging graphs.

December 23, 2024
Improve search results by calibrating model scoring in Elasticsearch
Learn how to leverage annotated data to calibrate semantic model scoring for better search results

December 19, 2024
Understanding optimized scalar quantization
In this post, we explain a new form of scalar quantization we've developed at Elastic that achieves state-of-the-art accuracy for binary quantization.
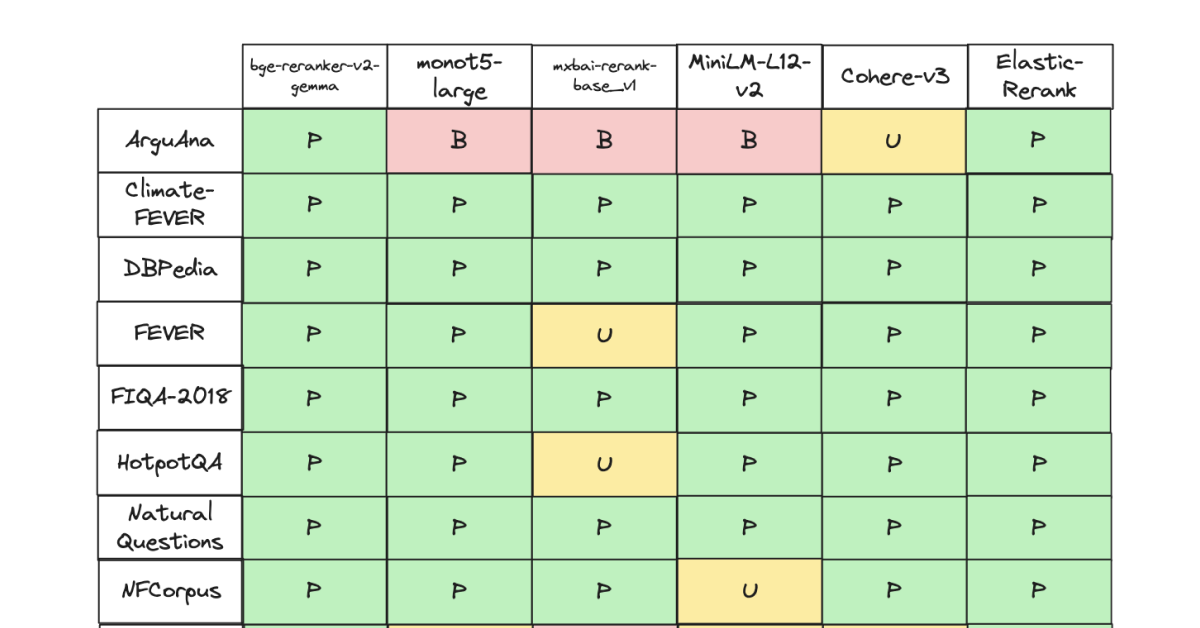
December 5, 2024
Exploring depth in a 'retrieve-and-rerank' pipeline
Select an optimal re-ranking depth for your model and dataset.