Hebrew is morphologically rich: Prefixes, inflections, and clitics make exact-token search brittle. This project provides an open-source Hebrew analyzer plugin for Elasticsearch 9.x that performs neural lemmatization in the analysis chain, using an embedded DictaBERT model executed in-process via ONNX Runtime with an INT8-quantized model.
Quick start
Download the relevant release or build and install (Linux build script generates Elasticsearch‑compatible zip):
./scripts/build_plugin_linux.shInstall in Elasticsearch:
/path/to/elasticsearch/bin/elasticsearch-plugin install file:///path/to/heb-lemmas-embedded-plugin-<ES_VERSION>.zipTest:
curl -k -X POST "https://localhost:9200/_analyze" \
-H "Content-Type: application/json" \
-u "elastic:<password>" \
-d '{"tokenizer":"whitespace","filter":["heb_lemmas","heb_stopwords"],"text":"הילדים אוכלים את הבננות"}'
Why Hebrew search is different
Hebrew is morphologically rich: Prefixes, suffixes, inflection, and clitics all collapse into a single surface form. That makes naive tokenization insufficient. Without true lemmatization, search quality suffers; users miss relevant results due to simple variations in form. This project tackles that by embedding a Hebrew lemmatization model inside the analyzer itself, so every token passes through a neural model before indexing and querying.
Example
Users may search for the lemma “בית” (house), but documents might contain:
- בית (a house)
- בבית (in the house)
- לבית (to the house)
- בבתים (in houses)
- לבתים (to houses)
Without lemmatization, these become different surface tokens; lemmatization normalizes them toward the same lemma (בית), improving recall:
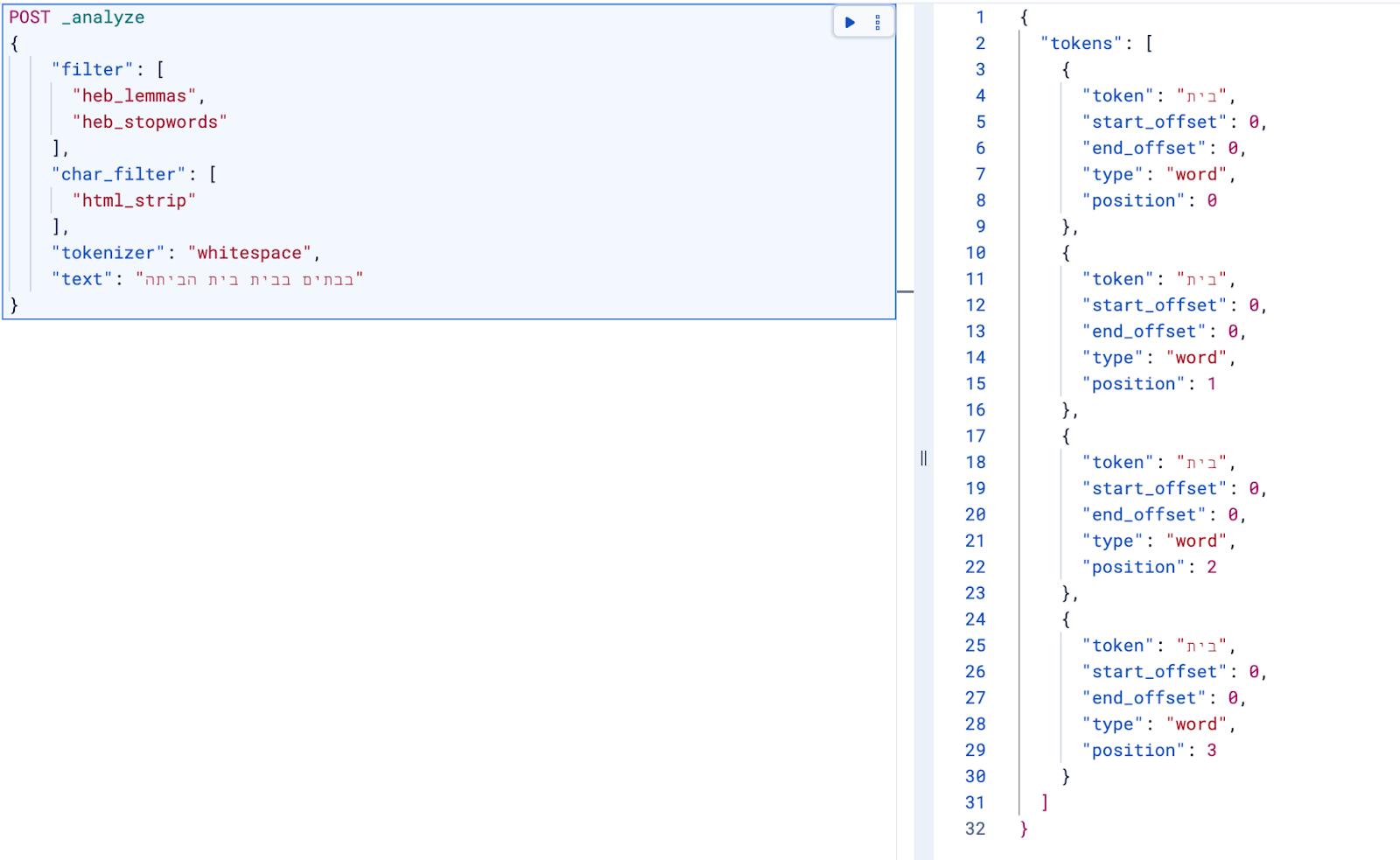
What this plugin does
Rather than relying on rule-based stemming, the analyzer runs a Hebrew lemmatization model as part of the Elasticsearch analysis chain and emits one normalized lemma per token. Because the model is neural, it can use local context within each analyzed segment to choose a lemma in ambiguous cases—while still producing stable tokens that work well for indexing and querying. The analyzer:
- Runs a Hebrew lemmatization model inside Elasticsearch.
- Produces better normalized tokens for Hebrew text.
- Supports stopwords and standard analyzer pipelines.
The result: Fast, reliable lemmatization
This analyzer is optimized for real‑world throughput:
- ONNX Runtime in‑process inference.
- INT8-quantized model for lower latency and memory footprint.
- Java Foreign Function Interface (FFI) for high‑performance native inference.
The result: fast, reliable lemmatization with predictable operational behavior.
To evaluate performance, we ran a benchmark in a Docker container (4 cores, 12 GB RAM) on 1 million large documents (5.7 GB of data) from the Hebrew Wikipedia dataset. You’ll find the results below:
| Metric (search) | Task | Value | Unit |
|---|---|---|---|
| Min throughput | hebrew-query-search | 409.75 | ops/s |
| Mean throughput | hebrew-query-search | 490.65 | ops/s |
| Median throughput | hebrew-query-search | 491.85 | ops/s |
| Max throughput | hebrew-query-search | 496.13 | ops/s |
| 50th percentile latency | hebrew-query-search | 7.02242 | ms |
| 90th percentile latency | hebrew-query-search | 10.7338 | ms |
| 99th percentile latency | hebrew-query-search | 19.0406 | ms |
| 99.9th percentile latency | hebrew-query-search | 27.165 | ms |
| 50th percentile service time | hebrew-query-search | 7.02242 | ms |
| 90th percentile service time | hebrew-query-search | 10.7338 | ms |
| 99th percentile service time | hebrew-query-search | 19.0406 | ms |
| 99.9th percentile service time | hebrew-query-search | 27.165 | ms |
| Error rate | hebrew-query-search | 0 | % |
Open source and Elastic‑ready
The plugin is fully open source and works on:
- Elastic open‑source distributions.
- Elastic Cloud.
You can build it yourself or download prebuilt releases and install it like any other plugin.
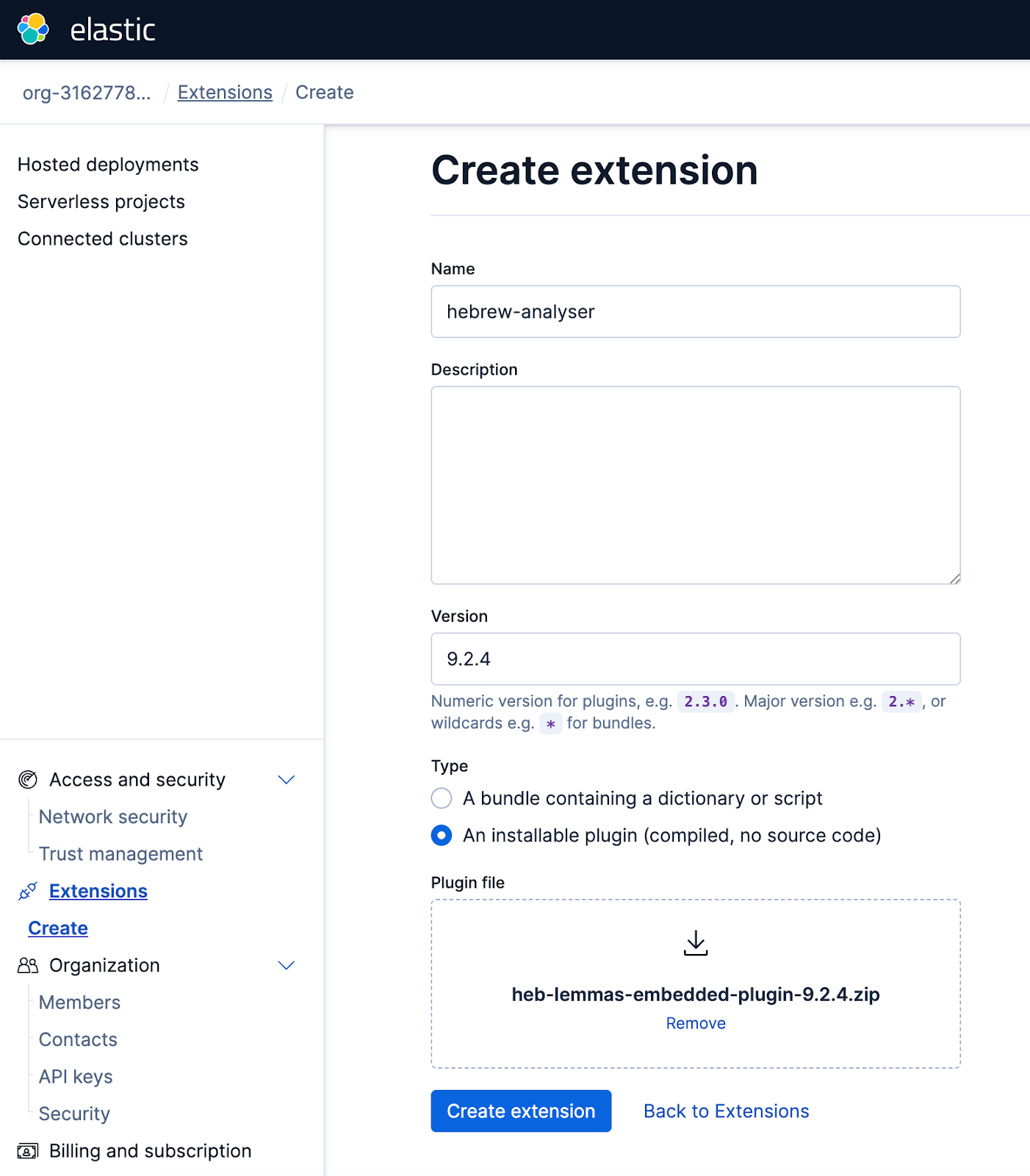
To upload the analyzer plugin to Elastic Cloud, navigate to the Extensions section within your Elastic Cloud console and proceed with the upload.
Credits
This project is a fork of the Korra ai Hebrew analysis plugin (MIT), which was implemented by Korra.ai with funding and guidance from the National NLP Program led by MAFAT and the Israel Innovation Authority.
This fork focuses on Elasticsearch 9.x compatibility and running lemmatization fully in-process via ONNX Runtime, using an INT8‑quantized model and bundled Hebrew stopwords. Lemmatization is powered by DictaBERT dicta-il/dictabert-lex (CC‑BY‑4.0).
Huge thanks to the Dicta team for making high-quality Hebrew natural language processing (NLP) models available to the community.
Links
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
March 31, 2026
From judgment lists to trained Learning to Rank (LTR) models
Learn how to transform judgment lists into training data for Learning To Rank (LTR), design effective features, and interpret what your model learned.

March 5, 2026
Does MCP make search obsolete? Not even close
Explore why search engines and indexed search remain the foundation for scalable, accurate, enterprise-grade AI, even in the age of MCP, federated search, and large context windows.

February 20, 2026
Ensuring semantic precision with minimum score
Improve semantic precision by employing minimum score thresholds. The article includes concrete examples for semantic and hybrid search.
January 30, 2026
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.