If you work with English search, standard text analysis usually just works. You index “running,” the analyzer strips the suffix to store “run,” and a user searching for “run” finds the document. Simple.
But if you work with languages like Hebrew, Arabic, German, or Polish, you know that standard rule-based analyzers often fail. They either under-analyze (missing relevant matches) or overanalyze (returning garbage results).

Wrong results when searching for “A black and white carpet” in a morphologically complex language. (Photo by yaed on Unsplash.)
For years, we’ve had to rely on complex dictionaries and fragile regex rules. Today, we can do better. By replacing rule-based logic with neural models for text analysis (small, efficient language models that understand context), we can drastically improve search quality.
Here’s how to solve the morphology challenge by using the Elasticsearch inference API and a custom model service.
The problem: Why rules fail
Most standard analyzers are context-free. They look at one word at a time and apply a static set of rules.
- Algorithmic analyzers (like Snowball) strip suffixes based on patterns.
- Dictionary analyzers (like Hunspell) look up words in a list.
This approach breaks down when the structure of a word (its root and affixes) changes based on the sentence it lives in.
1. The semitic ambiguity (roots versus prefixes)
Semitic languages, like Hebrew and Arabic, are built on root systems and often attach prepositions (such as, in, to, or from) directly to the word. This creates ambiguous tokens that rule-based systems cannot solve.
- Word:
בצל(B-Tz-L). - Context A: “The soup tastes better with onion (batzal).”
- Context B: “We sat in the shadow (ba-tzel) of the tree.”
In Context A, בצל is a noun (onion). In Context B, it’s a preposition ב (in) attached to the noun צל (shadow).
A standard analyzer is forced to guess. If it aggressively strips the ב prefix, it turns "onion" into "shadow." If it’s conservative and leaves it alone, a user searching for "shadow" (tzel) will fail to find documents containing "in the shadow" (batzel). Neural models solve this by reading the sentence to determine whether the ב is part of the root or a separate preposition.
2. The compound problem (German, Dutch, and more)
Languages like German, Dutch, Swedish, and Finnish concatenate nouns without spaces to form new concepts. This results in a theoretically infinite vocabulary. To search effectively, you must split (decompound) these words.
- Word:
Wachstube. - Split A:
Wach(guard) +Stube(room) = guardroom. - Split B:
Wachs(wax) +Tube(tube) = wax tube.
A dictionary-based decompounder acts blindly. If both “Wach” and “Wachs” are in its dictionary, it might pick the wrong split, polluting your index with irrelevant tokens.
To see this problem in English: A naive algorithm might split “carpet” into “car” + “pet.” Without understanding meaning, rules fail.

Photo by Bob Brewer on Unsplash.
The solution: “Neural analyzers” (neural models for text analysis)
We don’t need to abandon the inverted index. We just need to feed it better tokens.
Instead of a regex rule, we use a neural model (like BERT or T5) to perform the analysis. Because these models are trained on massive datasets, they understand context. They look at the surrounding words to decide whether בצל means "onion" or "in shadow" or if Wachstube belongs in a military or cosmetic context.
Architecture: The inference sidecar
We can integrate these Python-based models directly into the Elasticsearch ingestion pipeline using the inference API.
The pattern:
- External model service: A simple Python service (for example, FastAPI) hosts the model.
- Elasticsearch inference API: Defines this service as a custom model within Elasticsearch.
- Ingest pipeline: Sends text to the inference processor, which calls your Python service.
- Index mapping: Create a
whitespacetarget field for the analyzed text. - Indexing: The service returns the cleaned text, which Elasticsearch stores in the target field.
- Search: Queries are analyzed via the inference API before matching.

Implementation guide
Let’s build this for Hebrew (using DictaBERT) and German (using CompoundPiece).
To follow along, you’ll need:
- Python 3.10+.
- Elasticsearch 8.9.x+.
Install the Python dependencies:
pip3 install fastapi uvicorn torch transformersStep 1: External model service
To connect Elasticsearch to our neural model, we need a simple API service that:
- Receives text from the Elasticsearch inference API.
- Passes it through the neural model.
- Returns analyzed text in a format Elasticsearch understands.
This service interfaces Elasticsearch with the neural model. At ingest time, the Elasticsearch pipeline calls this API to analyze and store document fields; at search time, the application calls it to process the user's query. You can deploy this on any infrastructure, including EC2, Lambda, or SageMaker.
The code below loads both models at startup and exposes /analyze/hebrew and /analyze/german endpoints:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Union
from transformers import AutoTokenizer, AutoModel, AutoModelForSeq2SeqLM
from contextlib import asynccontextmanager
import torch
# Global models (loaded once at startup)
he_model = None
he_tokenizer = None
de_model = None
de_tokenizer = None
@asynccontextmanager
async def lifespan(app: FastAPI):
"""Load models at startup."""
global he_model, he_tokenizer, de_model, de_tokenizer
print("Loading Hebrew model (DictaBERT-Lex)...")
he_tokenizer = AutoTokenizer.from_pretrained("dicta-il/dictabert-lex")
he_model = AutoModel.from_pretrained("dicta-il/dictabert-lex", trust_remote_code=True)
he_model.eval()
print("Loading German model (CompoundPiece)...")
de_tokenizer = AutoTokenizer.from_pretrained("benjamin/compoundpiece")
de_model = AutoModelForSeq2SeqLM.from_pretrained("benjamin/compoundpiece")
if torch.cuda.is_available():
he_model.to("cuda")
de_model.to("cuda")
print("Models loaded successfully!")
yield
print("Shutting down...")
app = FastAPI(
title="Neural Text Analyzer",
description="Multi-language text normalization service",
version="1.0.0",
lifespan=lifespan
)
class InferenceRequest(BaseModel):
"""ES Inference API sends: {"input": ["text1", "text2"]} or {"input": "text"}"""
input: Union[str, List[str]]
def format_response(normalized_text: str) -> dict:
"""
Normalize output to OpenAI-compatible format for ES Inference API.
ES extracts: $.choices[*].message.content You do not need to stick
with the OpenAI output format.
Using it here for consistency reasons, since using the completions API.
"""
return {
"choices": [
{"message": {"content": normalized_text}}
]
}
@app.post("/analyze/hebrew")
async def analyze_hebrew(request: InferenceRequest):
"""Hebrew lemmatization using DictaBERT-Lex."""
global he_model, he_tokenizer
if he_model is None:
raise HTTPException(status_code=503, detail="Model not loaded")
# Handle input (can be string or list)
if isinstance(request.input, str):
texts = [request.input]
else:
texts = request.input
# Run prediction
with torch.no_grad():
results = he_model.predict(texts, he_tokenizer)
# results format: [[[word, lemma], [word, lemma], ...]]
if results and results[0]:
lemmas = []
for word, lemma in results[0]:
if lemma == '[BLANK]':
lemma = word
lemmas.append(lemma)
normalized = " ".join(lemmas)
else:
normalized = ""
return format_response(normalized)
@app.post("/analyze/german")
async def analyze_german(request: InferenceRequest):
"""German decompounding using CompoundPiece (supports 56 languages)."""
global de_model, de_tokenizer
if de_model is None:
raise HTTPException(status_code=503, detail="Model not loaded")
# Handle input
if isinstance(request.input, str):
text = request.input
else:
text = request.input[0] if request.input else ""
# Format: "de: <word>" for German
input_text = f"de: {text}"
inputs = de_tokenizer(input_text, return_tensors="pt")
if torch.cuda.is_available():
inputs = {k: v.to("cuda") for k, v in inputs.items()}
with torch.no_grad():
outputs = de_model.generate(**inputs, max_length=128)
# IMPORTANT: decode outputs[0], not outputs
result = de_tokenizer.decode(outputs[0], skip_special_tokens=True)
# Clean up: "de: Donau-Dampf-Schiff" -> "Donau Dampf Schiff"
# Note: model returns "de: " (with space after colon)
if result.startswith("de: "):
clean_result = result[4:].replace("-", " ")
elif result.startswith("de:-"):
clean_result = result[4:].replace("-", " ")
elif result.startswith("de:"):
clean_result = result[3:].replace("-", " ")
else:
clean_result = result.replace("-", " ")
return format_response(clean_result.strip())
@app.get("/health")
async def health():
return {"status": "healthy"}Save the code above to a file (for example, analyzer_service.py), and run:
python3 -m uvicorn analyzer_service:app --port 8000Wait for “Models loaded successfully!” (takes ~30–60 seconds for models to download on first run).
Test locally:
#Hebrew
curl -X POST http://localhost:8000/analyze/hebrew \
-H "Content-Type: application/json" \
-d '{"input": "הילדים אכלו גלידה בגינה"}'#German
curl -X POST http://localhost:8000/analyze/german \
-H "Content-Type: application/json" \
-d '{"input": "Donaudampfschifffahrt"}'Expected output:
- Hebrew: `{"choices":[{"message":{"content":"ילד אוכל גלידה גינה"}}]}`
- German: `{"choices":[{"message":{"content":"Donau Dampf Schiff Fahrt"}}]}`Step 2: Configure Elasticsearch inference API
We’ll use the custom inference endpoint. This allows us to define exactly how Elasticsearch talks to our Python endpoint.
Note: Use response.json_parser to extract the content from our normalized JSON structure. You do not need to stick with the OpenAI output format. We’re using it here for consistency reasons, since we’re using the completion task type, which is text to text.
Exposing your local service
For testing, we’ll use ngrok to expose the local Python service to the internet. This allows any Elasticsearch deployment (self-managed, Elastic Cloud, or Elastic Cloud Serverless) to reach your service.
Install and run ngrok:
# Install ngrok (macOS) (Or download from https://ngrok.com/download)
brew install ngrokExpose your local service:
ngrok http 8000ngrok will display a forwarding URL like:
Forwarding https://abc123.ngrok.io -> http://localhost:8000
Copy the HTTPS URL. You’ll use this in the Elasticsearch configuration.
Configure the inference endpoint
PUT _inference/completion/hebrew-analyzer
{
"service": "custom",
"service_settings": {
"url": "https://abc123.ngrok.io/analyze/hebrew",
"headers": {
"Content-Type": "application/json"
},
"request": "{\"input\": ${input}}",
"response": {
"json_parser": {
"completion_result": "$.choices[*].message.content"
}
}
}
}Replace https://abc123.ngrok.io with your actual ngrok URL.
Note: ngrok is used here for fast testing and development. The free tier has request limits, and URLs change on restart. For production, deploy your service to a persistent infrastructure.
For production (with API Gateway)
In production, deploy your Python service to a secure, persistent endpoint (such as AWS API Gateway + Lambda, EC2, ECS, or any cloud provider). Use secret_parameters to securely store API keys:
PUT _inference/completion/hebrew-analyzer
{
"service": "custom",
"service_settings": {
"url": "https://your-api-gateway.execute-api.region.amazonaws.com/prod/analyze/hebrew",
"headers": {
"x-api-key": "${api_key}",
"Content-Type": "application/json"
},
"secret_parameters": {
"api_key": "YOUR-API-KEY"
},
"request": "{\"input\": ${input}}",
"response": {
"json_parser": {
"completion_result": "$.choices[*].message.content"
}
}
}
}Step 3: Ingest pipeline
Create a pipeline that passes the raw text field to our model and stores the result in a new field.
PUT _ingest/pipeline/hebrew_analysis_pipeline
{
"description": "Lemmatizes Hebrew text using a custom inference endpoint",
"processors": [
{
"inference": {
"model_id": "hebrew-analyzer",
"input_output": {
"input_field": "content",
"output_field": "content_analyzed"
}
}
}
]
}Step 4: Index mapping
This is the most critical step. The output from our neural model is already analyzed. We do not want a standard analyzer to mess it up again. We use the whitespace analyzer to simply tokenize the text we received.
PUT /my-hebrew-index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "standard"
},
"content_analyzed": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}Step 5: Indexing
Option A: Single document.
POST /my-hebrew-index/_doc?pipeline=hebrew_analysis_pipeline
{
"content": "הילדים אכלו גלידה בגינה"
}Option B: Reindex existing data.
If you have existing data in another index, reindex it through the pipeline:
POST _reindex
{
"source": {
"index": "my-old-index"
},
"dest": {
"index": "my-hebrew-index",
"pipeline": "hebrew_analysis_pipeline"
}
}Option C: Set pipeline as default for index.
Make all future documents automatically use the pipeline:
PUT /my-hebrew-index/_settings
{
"index.default_pipeline": "hebrew_analysis_pipeline"
}Then index normally (no ?pipeline= needed):
POST /my-hebrew-index/_doc
{
"content": "הילדים אכלו גלידה בגינה"
}Step 6: Search
Search using a neural analyzer in Elasticsearch is a two-step process, so analyze the query first using the inference API, and then search with the result:
A. Analyze the query.
POST _inference/completion/hebrew-analyzer
{
"input": "הילדים אכלו גלידה בגינה"
}B. Search with the result.
GET /my-hebrew-index/_search
{
"query": {
"match": {
"content_analyzed": "ילד אוכל גלידה גינה"
}
}
}In production, wrap these two calls in your application code for a seamless experience.
Available models
The architecture above works for any language. You simply swap the Python model and adjust the post-processing of the output. Here are verified models for common complex languages:
- Hebrew: Context-aware lemmatization. Handles prefix ambiguity (ב, ה, ל, and more) dicta-il/dictabert-lex.
- German: Generative decompounding. Supports 56 languages, including Dutch, Swedish, Finnish, and Turkish. benjamin/compoundpiece.
- Arabic: BERT-based disambiguation and lemmatization for Modern Standard Arabic. CAMeL Tools.
- Polish: Case-sensitive lemmatization for Polish inflections. amu-cai/polemma-large.
Conclusion
You don’t need to choose between the precision of lexical search and the intelligence of AI. By moving the “smart” part of the process into the analysis phase using the inference API, you fix the root cause of poor search relevance in complex languages.
The tools are here. The models are open-source. The pipelines are configurable. It’s time to teach our search engines to read.
Code
All code snippets from this article are available at https://github.com/noamschwartz/neural-text-analyzer.
References:
- https://www.elastic.co/docs/api/doc/elasticsearch/operation/operation-inference-put-custom
- https://www.elastic.co/docs/manage-data/ingest/transform-enrich/ingest-pipelines
- https://ngrok.com
- https://huggingface.co/dicta-il/dictabert-lex
- https://huggingface.co/benjamin/compoundpiece
- https://arxiv.org/pdf/2305.14214
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
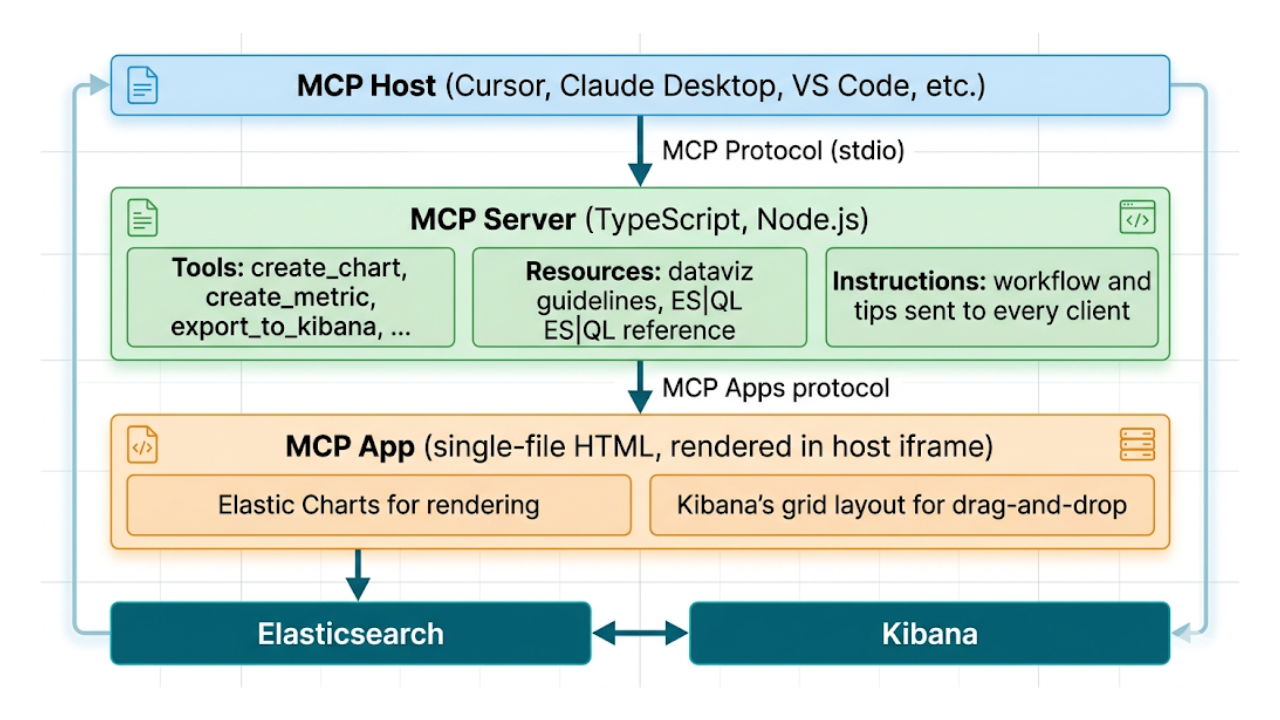
Describe it, don't draw it: AI-native Kibana dashboards via MCP and ES|QL
From prompt to dashboard. Learn how to build Kibana dashboards with natural language, using example-mcp-dashbuilder: an open source MCP application that writes ES|QL queries, creates interactive charts and exports fully functional dashboards directly to Kibana.

March 13, 2026
Entity resolution with Elasticsearch, part 4: The ultimate challenge
Solving and evaluating entity resolution challenges in a highly diverse “ultimate challenge” dataset designed to prevent shortcuts.

March 4, 2026
Entity resolution with Elasticsearch, part 3: Optimizing LLM integration with function calling
Learn how function calling enhances LLM integration, enabling a reliable and cost-efficient entity resolution pipeline in Elasticsearch.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.