Overview
In this article, you will learn how to combine BM25 relevance with real business metrics like profit margin and popularity using Elasticsearch’s function_score query. This step-by-step guide shows how to control scaling with logarithmic boosts and allows full explainability for each ranking calculation.
Introduction
In many use cases, search results focus on lexical (keyword) and semantic (meaning-based) analysis to find the content that most accurately and authoritatively answers a user’s query. However, e-commerce search is a bit more complex.
Results must reflect the shopper’s intent and incorporate business objectives such as profit margin, product popularity, or other factors that don’t always directly align with purely lexical or semantic matching.
While text relevance ensures customer satisfaction, ranking by profitability and popularity turns search into a business optimization engine.
In order to demonstrate how business signals can be incorporated into search results, in this post we’ll explore:
- How to boost product rankings by margin (profitability 0% to 200% in the demo data below).
- How to extend that same logic to include popularity (number of sales).
Once you understand how to boost by margin and popularity, extending search to incorporate other signals is straightforward.
Setup
Below is a small dataset you can paste directly into Dev Tools to follow along.
POST _bulk
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "MCC-HOME-500", "description": "McCain Home Chips 500g - High Margin", "margin": 200, "popularity": 100 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "MCC-HOME-1000", "description": "McCain Home Chips 1kg", "margin": 100, "popularity": 640 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "MCC-HOME-1500", "description": "McCain Home Chips 1.5kg", "margin": 50, "popularity": 10000 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "BIR-CHIPS-450", "description": "BirdsEye Crispy Chips 450g", "margin": 9, "popularity": 880 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "BIR-CHIPS-900", "description": "BirdsEye Crispy Chips 900g", "margin": 12, "popularity": 720 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "TRE-MINT-33", "description": "Trebor Peppermint 33g", "margin": 5, "popularity": 1100 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "TRE-MINT-4X38", "description": "Trebor Peppermint 4x38g", "margin": 8, "popularity": 680 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "TIC-MINT-16", "description": "TicTac Mint 16g", "margin": 3.5, "popularity": 980 }
{ "index": { "_index": "blog_food_products" } }
{ "product_id": "TIC-MINT-6X16", "description": "TicTac Mint 6x16g", "margin": 7, "popularity": 640 }Each document represents a product with:
- margin: profit margin (percent)
- popularity: relative sales volume (e.g. weekly average, or last week’s sum)
Ranking without margin
We can see how baseline results look by executing a simple query for “McCain chips” that does not take into consideration margin, as follows:
POST blog_food_products/_search
{
"size": 5,
"_source": ["description", "margin"],
"query": {
"match": {
"description" : "McCain Chips" }
}
}
Which returns the following results:
{
"_index": "blog_food_products",
"_id": "GKO3MJoBBtzDfCS5JfQM",
"_score": 1.6089411,
"_source": {
"description": "McCain Home Chips 1kg",
"margin": 100
}
},
{
"_index": "blog_food_products",
"_id": "GaO3MJoBBtzDfCS5JfQM",
"_score": 1.6089411,
"_source": {
"description": "McCain Home Chips 1.5kg",
"margin": 50
}
},
{
"_index": "blog_food_products",
"_id": "F6O3MJoBBtzDfCS5JfQM",
"_score": 1.3280699,
"_source": {
"description": "McCain Home Chips 500g - High Margin",
"margin": 200
}
},
{
"_index": "blog_food_products",
"_id": "GqO3MJoBBtzDfCS5JfQM",
"_score": 0.5837885,
"_source": {
"description": "BirdsEye Crispy Chips 450g",
"margin": 9
}
},
{
"_index": "blog_food_products",
"_id": "G6O3MJoBBtzDfCS5JfQM",
"_score": 0.5837885,
"_source": {
"description": "BirdsEye Crispy Chips 900g",
"margin": 12
}
}As you can see from the above results, the high margin version of the chips is 3rd in the results because the ordering does not consider margin.
Ranking by margin
Without any additional context, all sizes of “McCain chips” look equally relevant — but from a business perspective, it is possible that the higher-margin items should rank higher.
| Product | Margin (%) | Description |
|---|---|---|
| McCain Home Chips 500g – High Margin | 200% | small pack |
| McCain Home Chips 1kg | 100% | mid pack |
| McCain Home Chips 1.5kg | 50% | family pack |
We’ll use Elasticsearch’s function_score query to apply a margin-based boost.
POST blog_food_products/_search
{
"size": 5,
"explain": false, // keep only for tuning
"_source": ["description", "margin"],
"query": {
"function_score": {
/* ───────────────────────────────────────────────
* Base query
* Replace with your actual BM25 or semantic query.
* ─────────────────────────────────────────────── */
"query": {
"match": {
"description" : "McCain Chips" }
},
/* ───────────────────────────────────────────────
* Margin-driven boost
* ------------------------------------------------
* Elasticsearch computes (for the ln1p modifier):
*
* log_margin = ln(1 + margin * factor)
* boost = 1 + log_margin // +1 baseline via explicit { "weight": 1 }
* final_score = BM25 * boost
*
* Picking `factor` to cap around 2× at max_margin ≈ 200:
*
* 1 + ln(1 + factor * 200) ≈ 2
* ln(1 + 200*factor) = 1
* 1 + 200*factor = e
* factor = (e - 1) / 200 ≈ 0.00859
*
* You can keep a little headroom, e.g. use 0.0085.
* ─────────────────────────────────────────────── */
"functions": [
{
"filter": { "range": { "margin": { "gt": 0 } } },
"field_value_factor": {
"field" : "margin",
"modifier": "ln1p", // natural log of (1 + margin * factor)
"factor" : 0.0085, // ≈ (e - 1) / 200
"missing" : 0
}
},
{ "weight": 1 } // explicit neutral baseline (keeps zero/small margins neutral)
],
"score_mode": "sum", // boost = 1 + ln(1 + margin*factor) (sum of the two functions)
"boost_mode": "multiply" // final_score = BM25 × boost
// "max_boost": 2.0 // optional: clamp hard ceiling
}
}
}The above query results in the following, which reflect the impact of the margin boosting on the score. Notice that, as we intended, the high-margin McCain Chips have been boosted to the 1st position in the results.
{
"_index": "blog_food_products",
"_id": "F6O3MJoBBtzDfCS5JfQM",
"_score": 2.6471777,
"_source": {
"description": "McCain Home Chips 500g - High Margin",
"margin": 200
}
},
{
"_index": "blog_food_products",
"_id": "GKO3MJoBBtzDfCS5JfQM",
"_score": 2.5987387,
"_source": {
"description": "McCain Home Chips 1kg",
"margin": 100
}
},
{
"_index": "blog_food_products",
"_id": "GaO3MJoBBtzDfCS5JfQM",
"_score": 2.1787827,
"_source": {
"description": "McCain Home Chips 1.5kg",
"margin": 50
}
},
{
"_index": "blog_food_products",
"_id": "G6O3MJoBBtzDfCS5JfQM",
"_score": 0.64049,
"_source": {
"description": "BirdsEye Crispy Chips 900g",
"margin": 12
}
},
{
"_index": "blog_food_products",
"_id": "GqO3MJoBBtzDfCS5JfQM",
"_score": 0.62682253,
"_source": {
"description": "BirdsEye Crispy Chips 450g",
"margin": 9
}
}Understanding the formula
The function_score query allows us to apply a smooth, interpretable boost based on margin without overwhelming BM25’s lexical relevance.
Here’s how it works:
- margin_boost = ln(1 + margin × factor)
- boost = 1 + margin_boost
- final_score = BM25 × boost
Where the query is specified with the following fields:
- field_value_factor – uses a document field to influence scoring without scripting overhead.
- modifier: “ln1p” – computes ln(1 + margin × factor)
- Note: ln1p(x) is shorthand for ln(1 + x).
- factor – controls scale; 0.0085 caps boosts near 2× at margin=200.
- weight: 1 – ensures a minimum boost of 1 for neutral items.
- score_mode: “sum” – adds constant 1 (from that standalone “weight” : 1) and the margin_boost together.
- boost_mode: “multiply” – multiplies BM25 by the computed boost.
Why was that formula chosen?
The logarithmic (ln1p) scaling behaves well across real-world data:
- It grows fast at small margins (rewarding incremental gains).
- It flattens at high margins (preventing runaway scores).
- It’s continuous and interpretable — no thresholds or discontinuities.
| Margin | ln(1 + margin × 0.0085) | Boost (≈1+ln1p) | Boost Multiplier |
|---|---|---|---|
| 5 | 0.042 | 1.04 | ×1.04 |
| 50 | 0.35 | 1.35 | ×1.35 |
| 100 | 0.63 | 1.63 | ×1.63 |
| 200 | 0.99 | 1.99 | ×1.99 |
Ranking by margin and popularity
We can extend the same logic to add a popularity boost. Here, we tune the popularity factor so that the boost increases by roughly +1.0, at a popularity of 10,000. (These thresholds depend on your dataset’s scale.)
POST blog_food_products/_search
{
"size": 5,
"_source": ["product_id", "description", "margin", "popularity"],
"query": {
"function_score": {
"query": {
"match": {
"description": "McCain Chips" }
},
"functions": [
{
// calculate margin_boost
"filter": { "range": { "margin": { "gt": 0 } } },
"field_value_factor": {
"field": "margin",
"modifier":"ln1p", // ln(1 + margin * margin_f)
"factor": 0.008591, // ≈ (e - 1) / 200
"missing": 0
},
"weight": 1 // full impact from margin
},
{
// calculate popularity_boost
"filter": { "range": { "popularity": { "gt": 0 } } },
"field_value_factor": {
"field": "popularity",
"modifier":"ln1p", // ln(1 + popularity * popularity_f)
"factor": 0.0001718, // ≈ (e - 1) / 10,000
"missing": 0
},
"weight": 0.5 // popularity counts for half the impact of margin
},
{
"weight": 1 // ensures minimum boost of 1
}
],
"score_mode": "sum", // boost = 1 + margin_boost + 0.5×popularity_boost
"boost_mode": "multiply" // final_score = BM25 * boost
// "max_boost": 4.0 // optional: clamp hard ceiling
}
}
}Which returns results with the most popular product in 1st place, even though it is not the highest margin, as follows — in this case, the impact of the popularity boost has pushed up McCain Home Chips 1.5kg to 1st place.
{
"_index": "blog_food_products",
"_id": "IqPBMJoBBtzDfCS5CvRg",
"_score": 2.988299,
"_source": {
"product_id": "MCC-HOME-1500",
"description": "McCain Home Chips 1.5kg",
"margin": 50,
"popularity": 10000
}
},
{
"_index": "blog_food_products",
"_id": "IaPBMJoBBtzDfCS5CvRg",
"_score": 2.6905532,
"_source": {
"product_id": "MCC-HOME-1000",
"description": "McCain Home Chips 1kg",
"margin": 100,
"popularity": 640
}
},
{
"_index": "blog_food_products",
"_id": "IKPBMJoBBtzDfCS5CvRg",
"_score": 2.667411,
"_source": {
"product_id": "MCC-HOME-500",
"description": "McCain Home Chips 500g - High Margin",
"margin": 200,
"popularity": 100
}
},
{
"_index": "blog_food_products",
"_id": "JKPBMJoBBtzDfCS5CvRg",
"_score": 0.67510986,
"_source": {
"product_id": "BIR-CHIPS-900",
"description": "BirdsEye Crispy Chips 900g",
"margin": 12,
"popularity": 720
}
},
{
"_index": "blog_food_products",
"_id": "I6PBMJoBBtzDfCS5CvRg",
"_score": 0.66836256,
"_source": {
"product_id": "BIR-CHIPS-450",
"description": "BirdsEye Crispy Chips 450g",
"margin": 9,
"popularity": 880
}
}What the resulting boosts look like
The “factors” are tuned to add +1.0 to the boost at the assumed maximums. These are calculated to satisfy the following formulas:
ln(1 + 200 × margin_f) = 1.0
i.e. margin_f = 0.008592
ln(1 + 10 000 × popularity_f) = 1.0
i.e. popularity_f = 0.0001718Then:
margin_boost = ln(1 + margin × margin_f)
popularity_boost = ln(1 + popularity × popularity_f)
boost = 1 + margin_boost + 0.5 × popularity_boost
final_score = BM25 × boostEach cell in the table below represents the total BM25 multiplier for various margin and popularity values.

How to read the table:
- The first column (popularity = 0) isolates the margin effect.
- Moving right, popularity increases the boost — but since its weight is 0.5, its contribution to the summed boost is halved.
- Even at extreme values (popularity = 100,000), the boost flattens due to logarithmic scaling.
Tuning
If you find popularity can spike very high (e.g., 100k+) and you don’t want boosts above some ceiling, you can:
- Lower the popularity factor further, or
- Add “max_boost”: <cap> to function_score, or
- Split weights, e.g. “weight”: 0.25 on popularity and “weight”: 1 on margin (still with score_mode: “sum”), if you want one to dominate less.
Using rank_feature for similar use cases
At first glance, rank_feature and rank_features look like a natural choice for incorporating numeric signals such as popularity, recency, or even profit margin. They are fast, compressed, and easy to operationalize — which is why many teams reach for them first.
However, they are not a good fit for this type of scoring model, for the following reasons:
1. Rank-feature contributions are strictly additive
The score takes the form:
final_score = BM25 + feature_boostThis means the effect of the boost changes dramatically depending on the scale of the BM25 score.
- When BM25 is small, the boost dominates the ranking.
- When BM25 is large, the identical boost becomes negligible.
We need consistent, proportional behavior instead.
2. Impossible to express “percentage-based” or multiplicative logic
This article’s model requires expressing things like:
- “Popularity increases relevance by ~20%.”
- “Margin strengthens relevance but never overrides it.”
rank_feature cannot do this. It does not support multiplicative shaping of the BM25 score.
3. Combining multiple signals becomes unstable and hard to tune
If you try to combine margin, popularity, availability, or other business metrics via rank_features, each feature adds another independent additive term. These interact in opaque ways, making tuning brittle and unpredictable.
4. Bottom line
rank_feature is great for simple additive numeric boosts. It is not suitable when you need:
- stable behavior across queries
- proportional / multiplicative effects
- explainable blending of multiple signals
For this reason, the article uses function_score instead, because it provides explicit, controlled scoring that behaves consistently regardless of BM25 scale.
Wrapping up
Elastic’s function_score query makes it simple to transform search ranking from content relevance into business-aware optimization.
By combining BM25 relevance with economic signals like margin and popularity, you can:
- Align search with real business outcomes.
- Tune scaling via a single parameter (factor).
- Maintain full explainability through _
explain.
Once this foundation is in place, you can extend it to Stock levels (reduce the ranking of low-stock products), Recency (prioritize new products), or other business-critical signals that you want to take into consideration. Each new signal simply adds to the boost which is then multiplied by the base BM25 relevance score.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
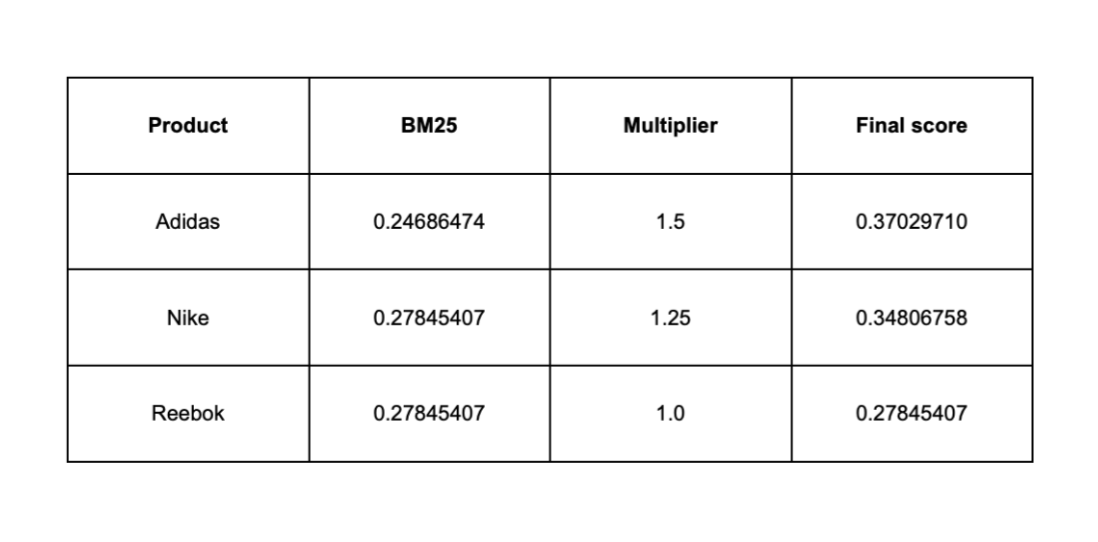
December 22, 2025
Influencing BM25 ranking with multiplicative boosting in Elasticsearch
Learn why additive boosting methods can destabilize BM25 rankings and how multiplicative scoring provides controlled, scalable ranking influence in Elasticsearch.

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.
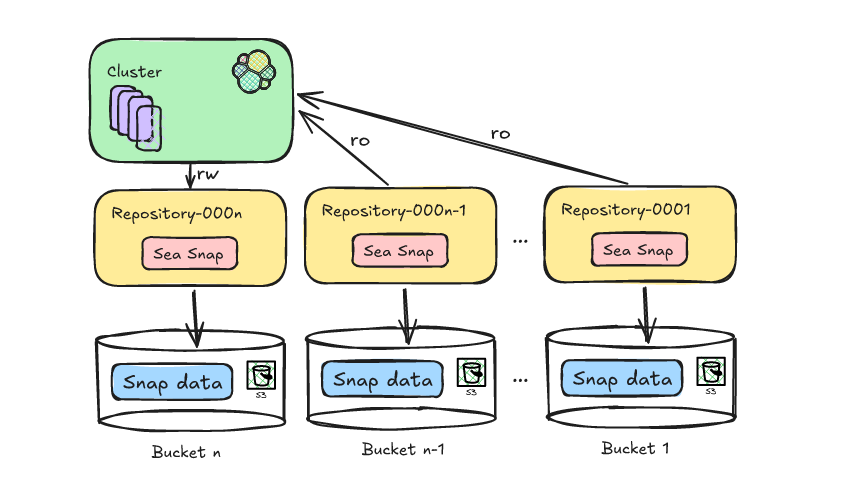
December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.
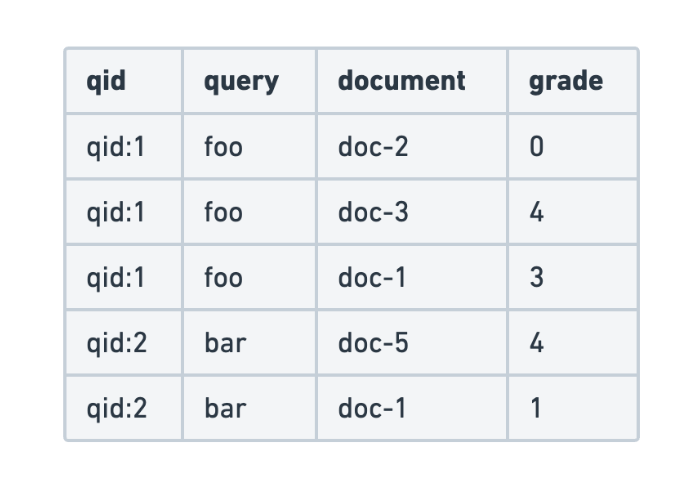
December 11, 2025
Evaluating search query relevance with judgment lists
Explore how to build judgment lists to objectively evaluate search query relevance and improve performance metrics such as recall, for scalable search testing in Elasticsearch.

December 8, 2025
How excessive replica counts can degrade performance, and what to do about it
Learn about the impact of high replica counts in Elasticsearch, and how to ensure cluster stability by right-sizing your replicas.