New models are released every week that surpass previous ones in intelligence, speed, or cost. This makes vendor lock-in risky and managing multiple connectors, billing accounts, and APIs unnecessarily complex. Each model behaves differently, in terms of token consumption, response latency, and compatibility with specific tool sets.
In this article, we'll build an AI-enriched audio products catalog, connect it to Elastic Agent Builder, and use OpenRouter to access different models while monitoring their performance across the entire workflow, from data ingestion to agent interactions.
Prerequisites
- Elastic Cloud 9.2 or Elastic Cloud Serverless
- Integration server with APM enabled
- OpenRouter account and API Key
- Python 3.9+
What is OpenRouter?
OpenRouter is a platform that unifies access to over 500 models from multiple providers through a single account and API. Instead of managing separate accounts for OpenAI, Anthropic, Google, and others, you access all of them through OpenRouter.
OpenRouter handles load balancing across providers, automatically routing requests to the provider with the best latency and fewest errors. You can also manually select providers or configure fallback chains. OpenRouter is compatible with standard APIs, code assistants, integrated development environments (IDEs), and more.
One key feature is Broadcast, which sends traces of your model usage to external observability systems. Since OpenRouter supports OpenTelemetry, we can monitor our complete pipeline plus any other OpenRouter usage costs in the Elastic Stack.
Architecture overview
We'll use an audio products catalog for which we generate new fields with AI using an inference ingest pipeline and then create an agent that can answer questions based on the indexed product data.
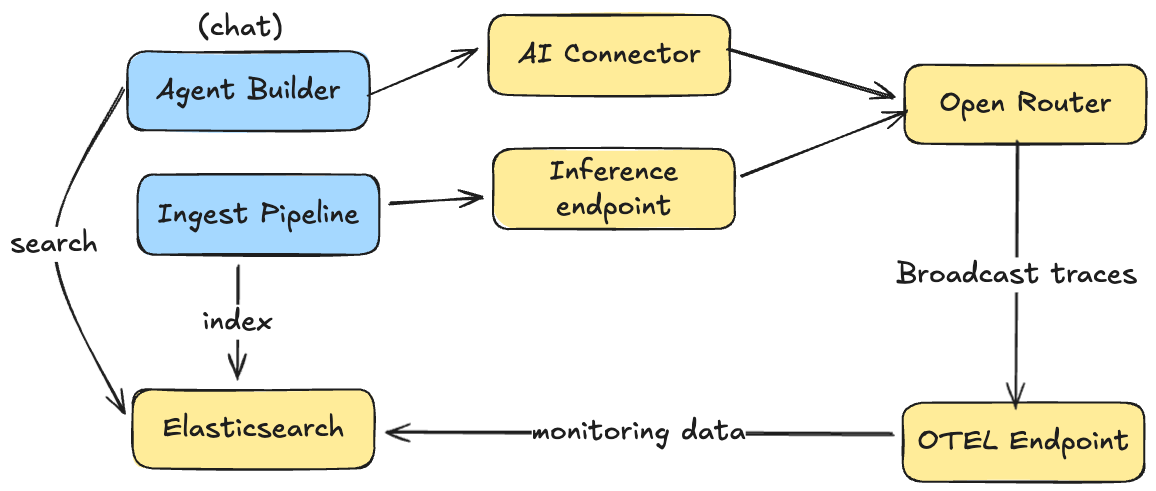
When ingesting data, the ingest pipeline uses an OpenRouter inference endpoint to generate new attribute fields based on the unstructured descriptions of the products, which triggers OpenRouter to send logs about that inference to Elasticsearch.
Similarly, when chatting with the Agent Builder that uses this data, logs are also sent to Elasticsearch for visualization.
We’ll use separate OpenRouter API keys for Agent Builder and ingestion:
OPENROUTER_API_KEYfor Agent Builder InteractionsOPENROUTER_INGESTION_KEYfor the inference pipeline
This allows us to differentiate traffic in monitoring dashboards and attribute costs to specific workflows.
Setup
First, we need to create an AI connector for the agent to interact with the large language model (LLM) and an inference endpoint for the ingest pipeline to extract fields from descriptions. Both connect to OpenRouter using the same API (but can use different keys for monitoring separation).
Create the AI connector
The AI connector allows Agent Builder to communicate with LLMs. We configure it to use OpenRouter as the provider:
import requests
import os
ELASTIC_URL = os.getenv("ELASTIC_URL")
KIBANA_URL = os.environ["KIBANA_URL"]
ELASTIC_API_KEY = os.environ["ELASTIC_API_KEY"]
OPENROUTER_API_KEY = os.environ["OPENROUTER_AGENT_KEY"]
OPENROUTER_INGESTION_KEY = os.environ.get("OPENROUTER_INGESTION_KEY", OPENROUTER_API_KEY)
# Create AI Connector for Agent Builder
connector_payload = {
"name": "OpenRouter Agent Connector",
"connector_type_id": ".gen-ai",
"config": {
"apiProvider": "Other",
"apiUrl": "https://openrouter.ai/api/v1/chat/completions",
"defaultModel": "openai/gpt-5.2",
"enableNativeFunctionCalling": True
},
"secrets": {
"apiKey": OPENROUTER_API_KEY
}
}
response = requests.post(
f"{KIBANA_URL}/api/actions/connector",
headers={
"kbn-xsrf": "true",
"Authorization": f"ApiKey {ELASTIC_API_KEY}",
"Content-Type": "application/json"
},
json=connector_payload
)
connector = response.json()
print(f"Connector created: {connector['id']}")We use a reasoning-capable model, like GPT-5.2, for the agent since it needs to handle complex queries and tool orchestration.
Create the inference endpoint
The inference endpoint allows Elasticsearch to call LLMs during data processing:
from elasticsearch import Elasticsearch
es = Elasticsearch(
hosts=[ELASTIC_URL],
api_key=ELASTIC_API_KEY,
request_timeout=60 # Higher timeout for inference operations
)
# Create inference endpoint for ingestion
inference_config = {
"service": "openai",
"service_settings": {
"model_id": "openai/gpt-4.1-mini",
"api_key": OPENROUTER_INGESTION_KEY,
"url": "https://openrouter.ai/api/v1/chat/completions"
}
}
response = es.inference.put(
inference_id="openrouter-inference-endpoint",
task_type="completion",
body=inference_config
)
print(f"Inference endpoint created: {response['inference_id']}")We use a fast, cheaper model, like GPT-4.1 Mini, for bulk ingestion tasks that don't require advanced reasoning capabilities.
Data pipeline
Let's configure the ingest pipeline. It will read from the product description field and extract structured categories that Agent Builder can use for filtering and aggregations.
For example, given this product description:
"Premium wireless Bluetooth headphones with active noise cancellation, 30-hour battery life, and premium leather ear cushions. Perfect for travel and office use."
We can extract:
- Category: Headphones
- Features: ["wireless", "noise_cancellation", "long_battery"]
- Use case: Travel
The key is providing possible values to the LLM as an enum so it groups consistently. Otherwise, we might get variations like "noise cancellation", "ANC", and "noise-canceling" that are harder to aggregate.
# Define the extraction prompt
EXTRACTION_PROMPT = (
"Extract audio product information from this description. "
"Return raw JSON only, no markdown, no explanation. Fields: "
"category (string, one of: Headphones/Earbuds/Speakers/Microphones/Accessories), "
"features (array of strings from: wireless/noise_cancellation/long_battery/waterproof/voice_assistant/fast_charging/portable/surround_sound), "
"use_case (string, one of: Travel/Office/Home/Fitness/Gaming/Studio). "
"Description: "
)
# Create the enrichment pipeline
pipeline_config = {
"processors": [
{
"script": {
"source": f"ctx.prompt = '{EXTRACTION_PROMPT}' + ctx.description"
}
},
{
"inference": {
"model_id": "openrouter-inference-endpoint",
"input_output": {
"input_field": "prompt",
"output_field": "ai_response"
}
}
},
{
"json": {
"field": "ai_response",
"add_to_root": True # Parses JSON and adds fields to document root
}
},
{
"remove": {
"field": ["prompt", "ai_response"]
}
}
]
}
es.ingest.put_pipeline(
id="product-enrichment-pipeline",
body=pipeline_config
)
print("Pipeline created: product-enrichment-pipeline")After using OpenAI to extract a JSON with the new attributes, we use the json processor to spread them into new fields.
Now let's index some sample audio products:
# Sample audio product data
products = [
{
"name": "Wireless Noise-Canceling Headphones",
"description": "Premium wireless Bluetooth headphones with active noise cancellation, 30-hour battery life, and premium leather ear cushions. Perfect for travel and office use.",
"price": 299.99
},
{
"name": "Portable Bluetooth Speaker",
"description": "Compact waterproof speaker with 360-degree surround sound. 20-hour battery life, perfect for outdoor adventures and pool parties.",
"price": 149.99
},
{
"name": "Studio Condenser Microphone",
"description": "Professional USB microphone with noise cancellation and voice assistant compatibility. Ideal for podcasting, streaming, and home studio recording.",
"price": 199.99
}
]
# Create index with mapping
es.indices.create(
index="products-enriched",
body={
"mappings": {
"properties": {
"name": {"type": "text"},
"description": {"type": "text"},
"price": {"type": "float"},
"category": {"type": "keyword"},
"features": {"type": "keyword"},
"use_case": {"type": "keyword"}
}
}
},
ignore=400 # Ignore if already exists
)
# Index products using the enrichment pipeline
for i, product in enumerate(products):
es.index(
index="products-enriched",
id=i,
body=product,
pipeline="product-enrichment-pipeline"
)
print(f"Indexed: {product['name']}")
# Refresh to make documents searchable
es.indices.refresh(index="products-enriched")Agent Builder
Now we can create an Agent Builder agent to use this index and answer both text questions and analytical queries using the new fields we've created:
# Create Agent Builder agent
agent_payload = {
"id": "audio-product-assistant",
"name": "Audio Product Assistant",
"description": "Answers questions about audio product catalog using semantic search and analytics",
"labels": ["audio"],
"avatar_color": "#BFDBFF",
"avatar_symbol": "AU",
"configuration": {
"tools": [
{
"tool_ids": [
"platform.core.search",
"platform.core.list_indices",
"platform.core.get_index_mapping",
"platform.core.execute_esql"
]
}
],
"instructions": """You are an audio product assistant that helps users find and analyze audio equipment.
Use the products-enriched index for all queries. The extracted fields are:
- category: Headphones, Earbuds, Speakers, Microphones, or Accessories
- features: array of product features like wireless, noise_cancellation, long_battery
- use_case: Travel, Office, Home, Fitness, Gaming, or Studio
For analytical questions, use ESQL to aggregate data.
For product searches, use semantic search on the description field."""
}
}
response = requests.post(
f"{KIBANA_URL}/api/agent_builder/agents",
headers={
"kbn-xsrf": "true",
"Authorization": f"ApiKey {ELASTIC_API_KEY}",
"Content-Type": "application/json"
},
json=agent_payload
)
agent = response.json()
print(f"Agent created: {agent['id']}")For tools, we use search for semantic queries and Elasticsearch Query Language (ES|QL) for analytical queries:
Now you can chat with your agent and ask questions like:
- "What headphones do we have for travel?"
- "Show me products with noise cancellation under $200"
- "What's the average price by category?"
The agent uses the AI-enriched fields to provide better filtering and aggregations.
Implementing OpenRouter Broadcast
Now let's set up inference monitoring. First, we need our OpenTelemetry endpoint URL. Navigate to the APM tutorial in Kibana:
https://<your_kibana_url>/app/observabilityOnboarding/otel-apm/?category=applicationCollect the URL and authentication token from the OpenTelemetry tab:
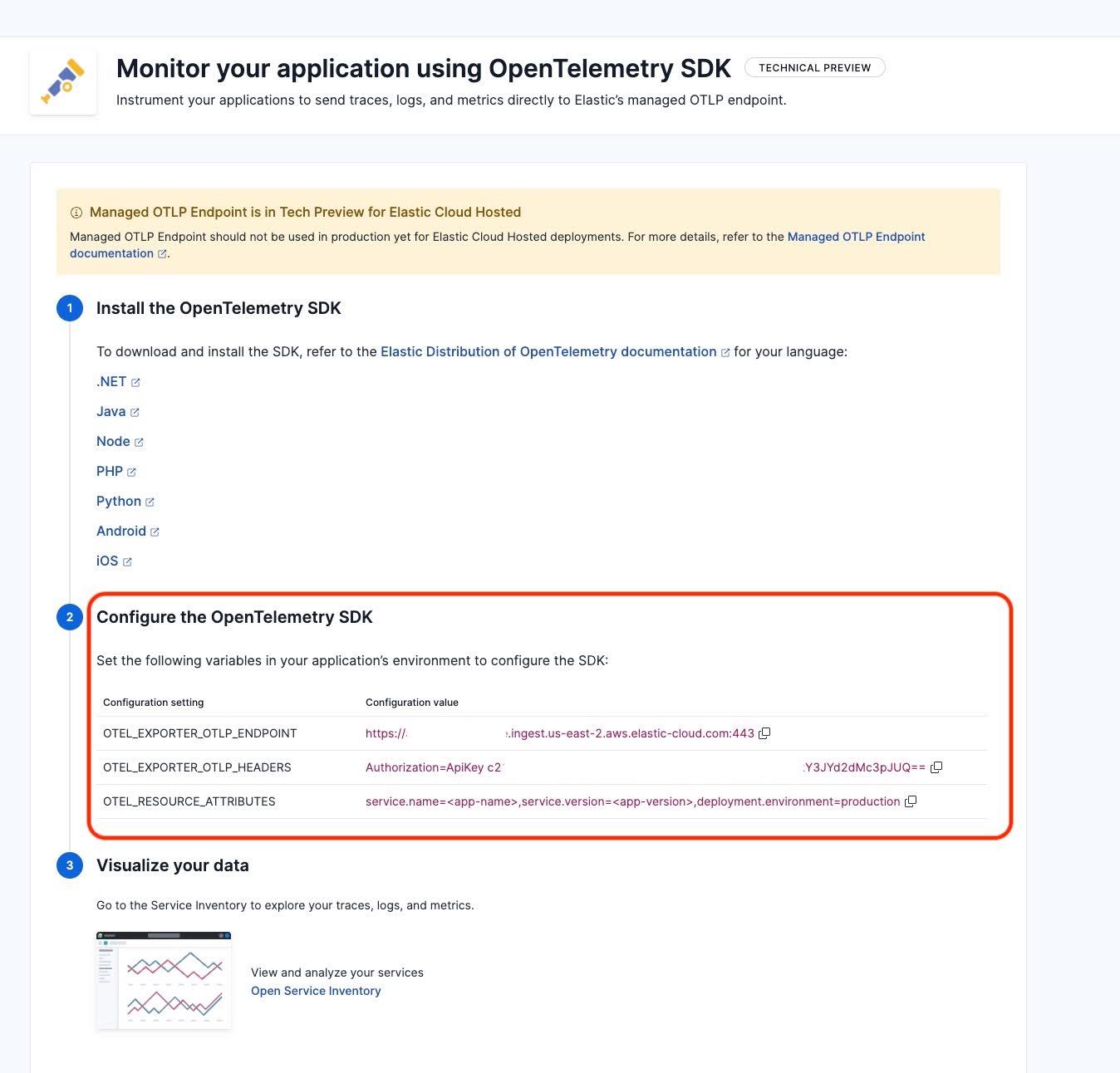
Important: Your Kibana server needs to be reachable via the public internet so that it can receive data from OpenRouter.
In OpenRouter, go to Broadcast settings and add a new destination for the "OpenTelemetry Collector":
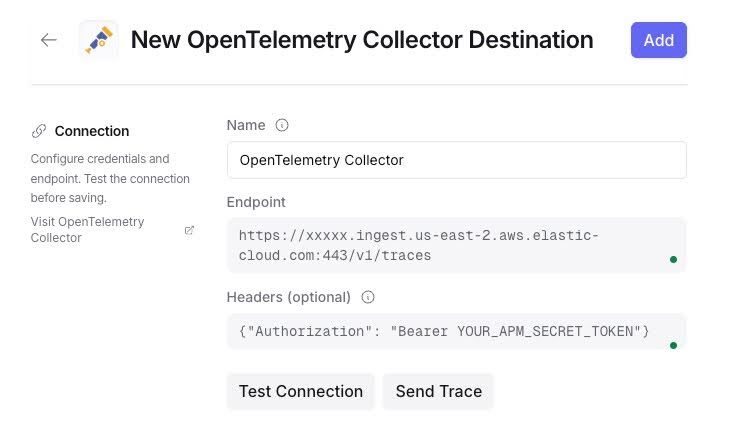
Important: Configure the endpoint with the /v1/traces path and authentication headers:
Endpoint: https://xxxxx.ingest.us-east-2.aws.elastic-cloud.com:443/v1/traces
Headers: {"Authorization": "Bearer YOUR_APM_SECRET_TOKEN"}Press Test connection, and you should see a success message.
Monitoring in Elastic
After using OpenRouter models, you should start seeing documents in Kibana. The indexed documents are in the data stream traces-generic.otel-default with service.name: "openrouter" and include information about:
- Request and response details.
- Token usage (prompt, completion, total).
- Cost (in USD).
- Latency (time to first token, total).
- Model information.
From now on, the activity of the inference pipeline and Agent Builder in relation to LLM usage will be recorded in OpenRouter and sent to Elastic.
Default APM dashboards
You can view the default dashboards in Kibana under Observability > Applications > Service Inventory > openrouter:
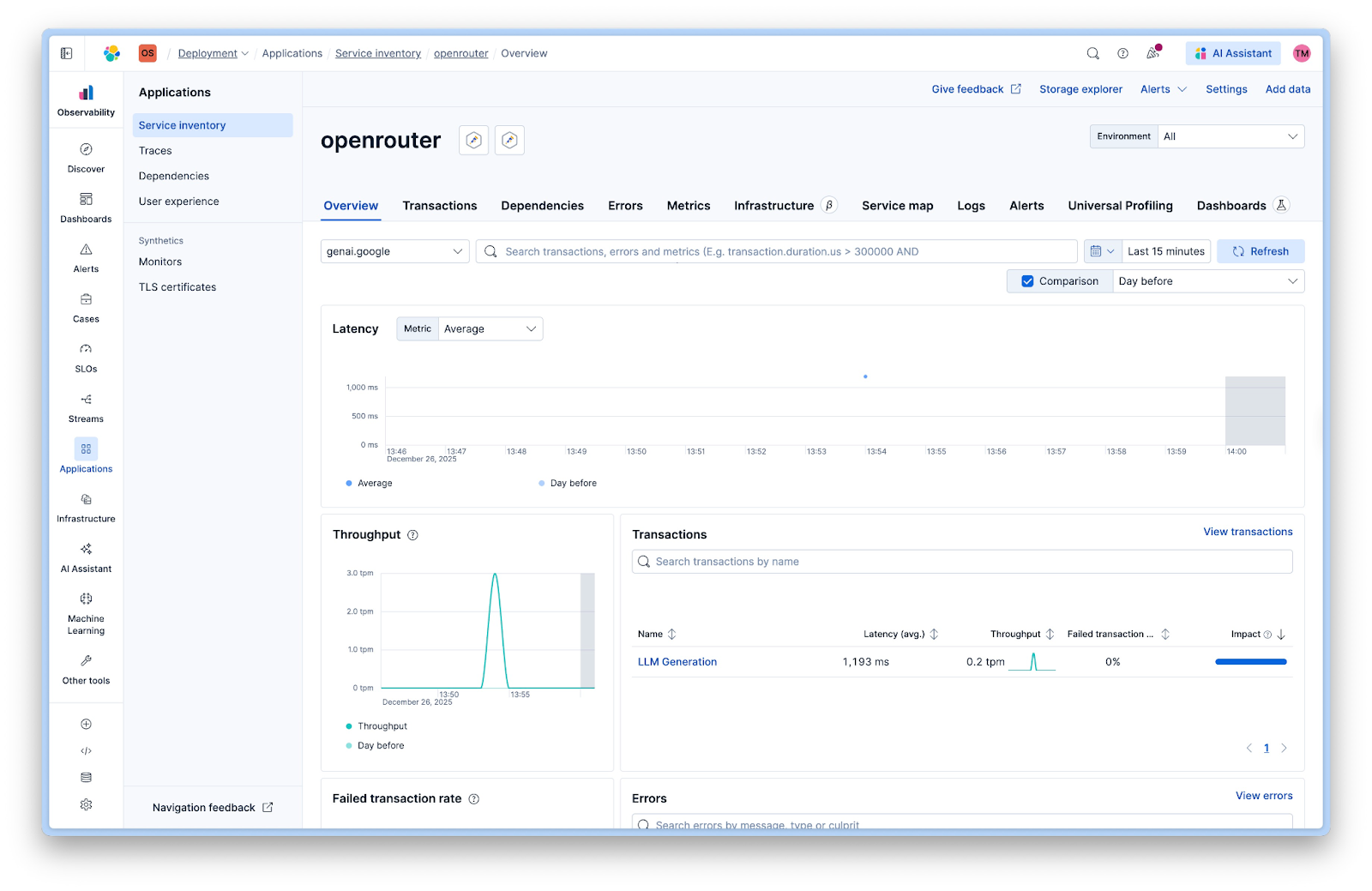
The service view shows:
- Latency: Average response times across all calls.
- Throughput: Requests per minute.
- Failed transactions: Error rates.
- Transactions: Breakdown by operation type.
Custom LLM monitoring dashboard
For more control over the information displayed, you can create a custom dashboard. We created one that differentiates ingestion from agent chat and measures relevant parameters, like token usage and cost, plus usage outside Elastic, like coding assistants via API key filters:
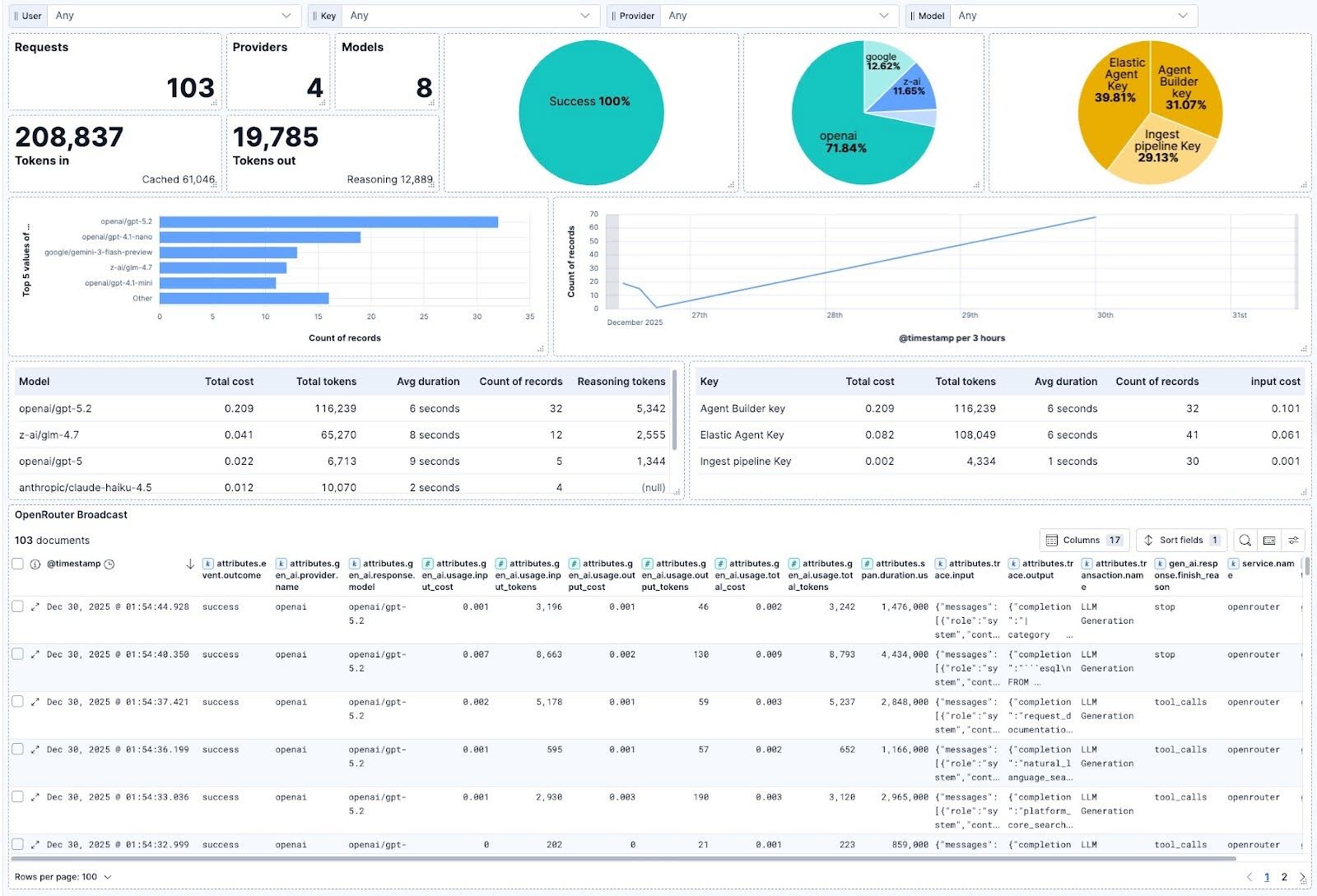
The dashboard shows:
- Success rate by workflow type.
- Token usage by model.
- Cost breakdown by API key.
- Latency trends over time.
- Model comparison metrics.
You can download the dashboard here and import it to your Kibana instance using Saved Objects import.
Conclusion
OpenRouter lets you move quickly and test multiple models and providers using the same API and billing account, making it convenient to compare models of different types—large parameter, small parameter, commercial, open source, and more.
Using OpenRouter Broadcast, we can effortlessly monitor the performance of these models during ingestion via ingest pipelines or chat via Agent Builder, plus combine it with OpenRouter usage for other purposes, like coding agents and apps.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

March 10, 2026
SearchClaw: Bring Elasticsearch to OpenClaw with composable skills
Give your local AI agent access to Elasticsearch data using OpenClaw, composable skills, and agents, no custom code required.

March 6, 2026
Build task-aware agents with an expanded model catalog on Elastic Inference Service (EIS)
Elastic Inference Service (EIS) expands its managed model catalog, enabling teams to build production-ready agents with flexible model choice across retrieval, generation, and reasoning, without managing GPUs or infrastructure.
March 9, 2026
Building effective database retrieval tools for context engineering
Best practices for writing database retrieval tools for context engineering. Learn how to design and evaluate agent tools for interacting with Elasticsearch data.

March 5, 2026
Does MCP make search obsolete? Not even close
Explore why search engines and indexed search remain the foundation for scalable, accurate, enterprise-grade AI, even in the age of MCP, federated search, and large context windows.
March 3, 2026
Using subagents and Elastic Agent Builder to bring business context into code planning
Learn about subagents, how to ensure they have the right information, and how to create a specialized subagent that connects Claude Code to your Elasticsearch data.