It’s hard to believe that Apache Lucene has been around for over a quarter of a century! Yes, more than 25 years of search enabled through Apache Lucene.
Community by the numbers
For contributions and the community as a whole, 2025 was another strong year, with 1,756 commits and 1,080 pull requests from 134 unique contributors. The community continued to grow this year, increasing the number of contributors by 98 from the previous year. The project management committee (PMC) and committer cohort also increased. Apache Lucene added nine new committers in 2025, one of whom was Elastic’s own Simon Cooper. (Congratulations, thecoop!) The PMC also welcomed two new members. Our little community continues to grow.
Our highlights
With almost 2,000 commits and eight releases, it’s difficult to summarize all the things that we loved from the year in Apache Lucene. But, not hiding from a challenge, here are some of our highlights.
The year of faster queries
In many ways, 2025 was the year Apache Lucene embraced better auto-vectorization, manual SIMD optimizations, and overall making things go faster. Lucene community member Adrien Grand goes into great detail in this blog, and below are links and summaries for the biggest jumps. As always, a huge shout-out to Mike McCandless for maintaining the Apache Lucene Benchmarks for years.
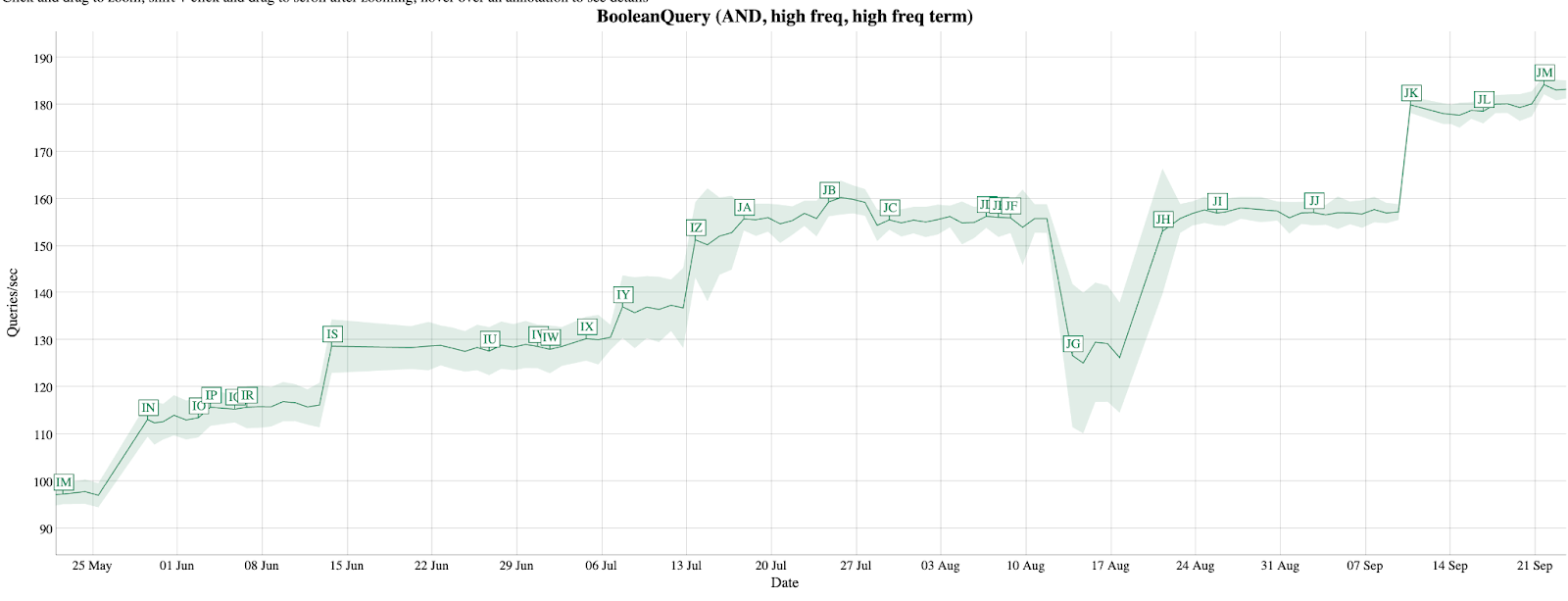
[IN]Refactor main top-n bulk scorers to evaluate hits in a more term-at-a-time fashion[IS]Irrelevant hardware update, so it’s just noise here[IY]Use branchless way to speedup filterCompetitiveHits[IZ]Improve collecting docs stored as bitsets[JA]Vectorize filterCompetitiveHits by hand with the Java Panama API[JK]Increase the document block size to 256
Discounting the hardware change [IS], this is almost a 60% increase in query speed in 2025, going from <100 queries per second (qps) to >170 qps.
Vector search
There were a number of vector search improvements in 2025. Three to highlight are improving filtered vector search with ACORN, adding optimistic multisegment search, and bulk scoring of vectors.
ACORN-1 is an interesting algorithm for graph-based vector indices. It has the significant benefit of being filter and algorithm-agnostic. Since Apache Lucene uses hierarchical navigable small world (HNSW) for its indexing and users generally want to just filter on anything and everything without additional configuration, it’s a perfect fit. A community member originally investigated adding this algorithm. (He has since been hired by Elastic. Hi, Ben! 👋👋👋) A nice balance was found for Lucene, providing faster filtered vector search without requiring significant work by the user in configuration and no additional indexing of information.
The addition of optimistic multisegment vector search to Apache Lucene really highlights how the community comes together to make it all happen. Three different individuals combined powers to debug, benchmark, design, and iterate on this solution. Originally proposed by Michael Sokolov (a vector search superstar in the Lucene community), it immediately caught my attention, too, because it claimed to fix our weird concurrency consistency bug without sacrificing performance. With some iteration and benchmarking by fellow community member Dzung Bui, we were able to strike the right balance in speed and recall, improving performance, making multithreaded searches consistent, and implementing a pretty neat algorithm.
Bulk scoring was born out of a collaboration between community member Trevor McCulloch and our very own Chris Hegarty and was introduced as a new scoring interface in PR #14978, with an initial float32 implementation following in PR #14980. Modern vector search involves thousands or even millions of comparisons as a query vector is evaluated against vectors in the index, often by traversing a graph of nearest neighbors. Traditionally, these comparisons are performed one vector at a time. Bulk scoring inverts that model by passing a batch of vectors, represented as ordinals in the index, to the scorer in a single call. This allows the scorer to prefetch and pipeline work across vectors, amortizing cache misses and reducing per-vector overhead. An exciting aspect of the original design discussion considered bulk scorers implemented in Rust and C. While Lucene itself remains a Java library, this opens the door to highly optimized, SIMD-friendly, native implementations.
We didn’t even get to talk about several other improvements that landed in this area, including HNSW optimizations, like more compact GroupVarInt graph encoding, bypassing graph construction for tiny segments, and continued reductions in memory footprint. On the operations side, Lucene now exposes off-heap memory requirements, making it easier to understand and debug native memory usage. While these changes are small(ish) individually, together they help make Lucene’s vector search faster, leaner, and easier to operate in production.
Bonus
The last highlight is a little out of place. It's a particularly frustrating but satisfying bug fix. I won’t go into deep details here, as it touches on how Lucene does max scoring and bulk scoring, applies filters, and handles all its internal iterator state. This deserves its own blog post. In short, we ran into this bug in production in late September 2025. It was surfacing as an EndOfFileException during a specific query execution. And then, like all fun bugs, it took a week or two of work to reproduce and fully debug. Finally, when we knew what exactly caused the exception to throw, we then had to dig into why to fix it. All in all, a month’s worth of work summarized in one line of code. Bask in its glory:
- top.doc = top.approximation.advance(filter.doc);
+ // Must use the iterator as `top` might be a two-phase iterator
+ top.doc = top.iterator.advance(filter.doc);Goodbye 2025, hello 2026
A big thank you to everyone in the Apache Lucene community who worked tirelessly to improve this venerable search library. We ❤️ you.
Ready to try this out on your own? Start a free trial.
Elasticsearch and Lucene offer strong vector database and search capabilities. Dive into our sample notebooks to learn more.
Related content

September 3, 2025
Vector search filtering: Keep it relevant
Performing vector search to find the most similar results to a query is not enough. Filtering is often needed to narrow down search results. This article explains how filtering works for vector search in Elasticsearch and Apache Lucene.

April 7, 2025
Speeding up merging of HNSW graphs
Explore the work we’ve been doing to reduce the overhead of building multiple HNSW graphs, particularly reducing the cost of merging graphs.

February 27, 2025
Filtered HNSW search, fast mode
Explore the improvements we have made for HNSW vector search in Apache Lucene through our ACORN-1 algorithm implementation.
February 7, 2025
Concurrency bugs in Lucene: How to fix optimistic concurrency failures
Thanks to Fray, a deterministic concurrency testing framework from CMU’s PASTA Lab, we tracked down a tricky Lucene bug and squashed it

January 7, 2025
Early termination in HNSW for faster approximate KNN search
Learn how HNSW can be made faster for KNN search, using smart early termination strategies.