Our inference tooling at Elastic has had some major power-ups this year with the introduction of our GPU-powered Elastic Inference Service (EIS), providing a platform for streamlined access to LLMs, embeddings, and reranker models via an always-on dedicated service.
Today, we’ll focus on how EIS can simplify the semantic search experience with our sparse embeddings model, ELSER (Elastic Learned Sparse EncodeR). Having semantic search in place as a foundation can help to unlock many additional abilities, including hybrid retrieval and being able to provide great context to LLMs for your agentic workflows.
Let’s get started!
Getting started with semantic search
You can now get started with your end-to-end semantic search use cases with the inference endpoints powered by EIS.
1. Create a semantic text field using the new endpoint
First, let’s create a new index using the semantic_text field type and the EIS inference id .elser-2-elastic.
PUT semantic-embeddings
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": ".elser-2-elastic"
}
}
}
}This sets up an index called semantic-embeddings where the content field automatically generates embeddings using the .elser-2-elastic inference endpoint.
In future versions, this inference id will be the default, so you won’t need to specify it explicitly.
2. Reindex your data
Next, let’s reindex an existing text index that contains national parks data so it can use the new semantic_text field via the index we just created.
This is a necessary step if you want to bring in existing data to an EIS-powered index, but will be simplified further in our next release to allow you to update an existing index mapping without reindexing.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "bm25-based-index",
"size": 100
},
"dest": {
"index": "semantic-embeddings"
}
}3. Search
Finally, let’s query the index for information about national parks via semantic search.
GET semantic-embeddings/_search
{
"query": {
"semantic": {
"field": "content",
"query": "Which park is most popular?"
}
}
}And the response:
{
"took": 168,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 17.655077,
"hits": [
{
"_index": "semantic-embeddings",
"_id": "ldJ9C5oBYmL2EI9TGdMP",
"_score": 17.655077,
"_source": {
"text": "Rocky Mountain National Park is one of the most popular national parks in the United States. It receives over 4.5 million visitors annually, and is known for its mountainous terrain, including Longs Peak, which is the highest peak in the park. The park is home to a variety of wildlife, including elk, mule deer, moose, and bighorn sheep. The park is also home to a variety of ecosystems, including montane, subalpine, and alpine tundra. The park is a popular destination for hiking, camping, and wildlife viewing, and is a UNESCO World Heritage Site."
}
},
{
"_index": "semantic-embeddings",
"_id": "k9J9C5oBYmL2EI9TGdMP",
"_score": 12.741274,
"_source": {
"text": "Yellowstone National Park is one of the largest national parks in the United States. It ranges from the Wyoming to Montana and Idaho, and contains an area of 2,219,791 acress across three different states. Its most famous for hosting the geyser Old Faithful and is centered on the Yellowstone Caldera, the largest super volcano on the American continent. Yellowstone is host to hundreds of species of animal, many of which are endangered or threatened. Most notably, it contains free-ranging herds of bison and elk, alongside bears, cougars and wolves. The national park receives over 4.5 million visitors annually and is a UNESCO World Heritage Site."
}
},
{
"_index": "semantic-embeddings",
"_id": "lNJ9C5oBYmL2EI9TGdMP",
"_score": 11.813252,
"_source": {
"text": "Yosemite National Park is a United States National Park, covering over 750,000 acres of land in California. A UNESCO World Heritage Site, the park is best known for its granite cliffs, waterfalls and giant sequoia trees. Yosemite hosts over four million visitors in most years, with a peak of five million visitors in 2016. The park is home to a diverse range of wildlife, including mule deer, black bears, and the endangered Sierra Nevada bighorn sheep. The park has 1,200 square miles of wilderness, and is a popular destination for rock climbers, with over 3,000 feet of vertical granite to climb. Its most famous and cliff is the El Capitan, a 3,000 feet monolith along its tallest face."
}
}
]
}
}And that’s all you need to do! With an EIS-powered semantic search index you get superior ingest performance, easy token-based pricing, and a service that’s available when you need it.
For a detailed example and tutorial, please refer to the Elastic docs for ELSER on EIS and the tutorial.
So how does this work?
The Elastic Inference Service runs on Elastic’s infrastructure, providing access to machine-learning models on demand.
The team used Ray to build out the service, specifically using the Ray Serve libraries to run our machine learning models. This runs on top of Kubernetes and uses pools of NVIDIA GPUs in the Elastic Cloud Platform to perform the model inference operations.
Ray gives us a lot of great benefits:
- It works out of the box with PyTorch, Tensorflow, and other ML libraries;
- It’s Python-native and supports custom business logic, allowing easy integration with models in the Python ecosystem;
- It’s robust and works across heterogeneous GPU pools, allowing fractional resource management;
- It supports response streaming, dynamic batching, and plenty of other useful features.
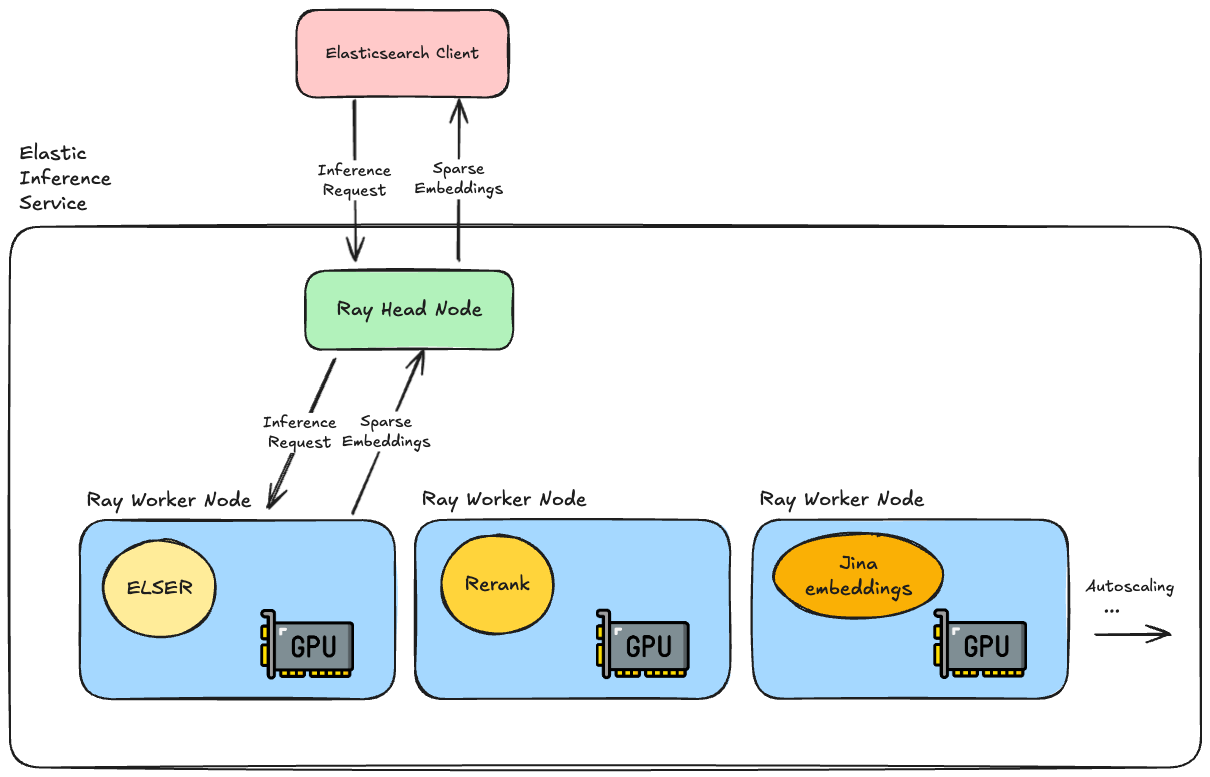
When an inference API request comes in for semantic search, we have the ELSER model up and running and ready to generate your sparse embeddings. Running on GPUs allows us to efficiently parallelise operations, which is particularly helpful if you have a lot of documents you need to ingest regularly.
What’s next?
In future versions of Elastic, ELSER via EIS will be the default semantic text setting, so you won’t even have to specify the inference id when you create the semantic index. We’ll be adding the ability to change an index to use semantic search via EIS without needing to do any reindexing. Finally, and most excitingly, we’ll be adding new models to support reranking and Jina’s multilingual and multimodal embedding models.
Stay tuned for future blog posts with further technical details of how the service works and more news about models and features!
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
December 22, 2025
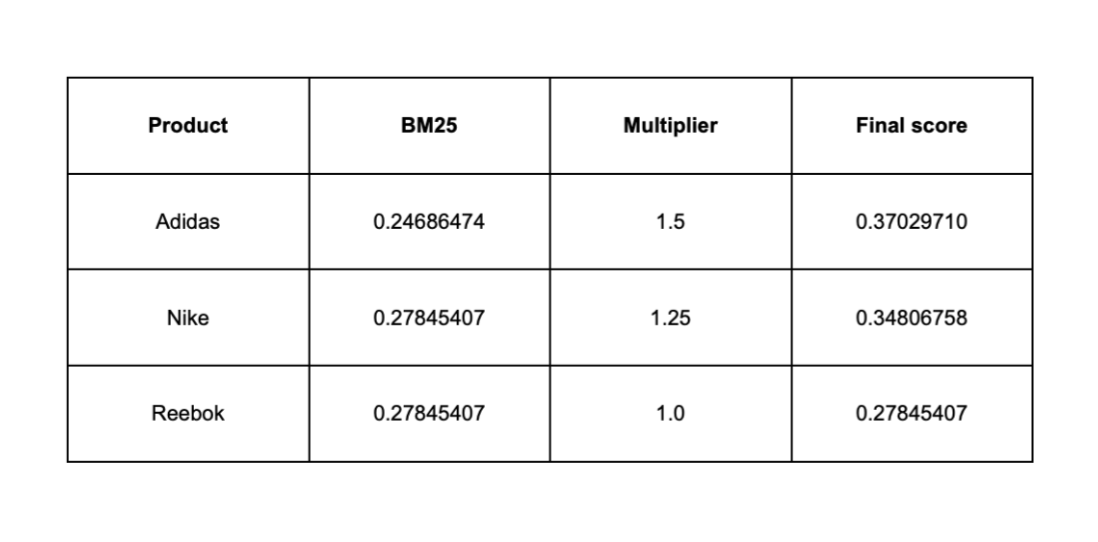
Influencing BM25 ranking with multiplicative boosting in Elasticsearch
Learn why additive boosting methods can destabilize BM25 rankings and how multiplicative scoring provides controlled, scalable ranking influence in Elasticsearch.

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.

December 17, 2025
Boosting e-commerce search by profit and popularity with the function score query in Elasticsearch
Discover how to optimize e-commerce search by blending BM25 relevance with profit margin and popularity signals in Elasticsearch using the function_score query.
December 16, 2025
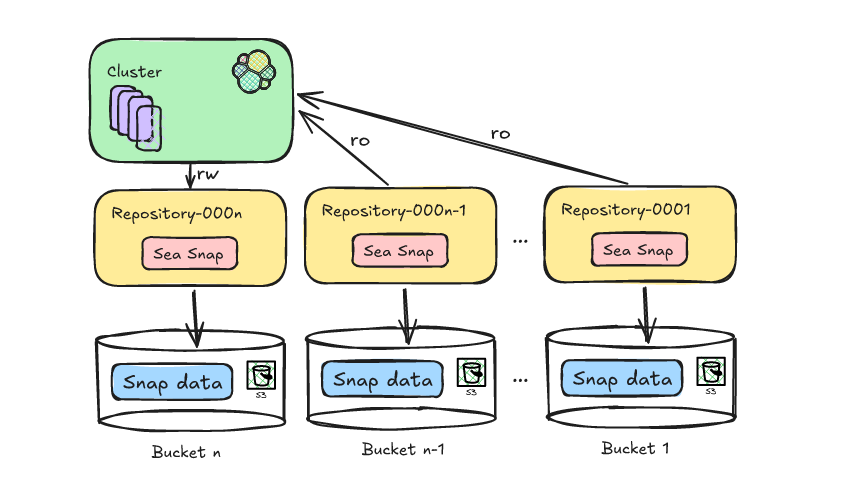
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.
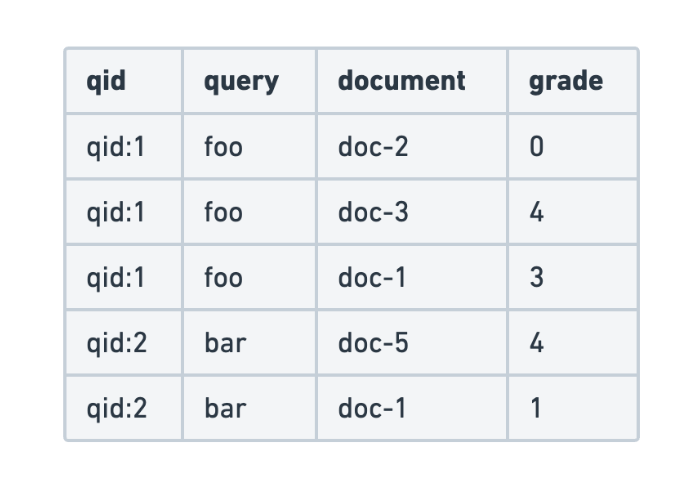
December 11, 2025
Evaluating search query relevance with judgment lists
Explore how to build judgment lists to objectively evaluate search query relevance and improve performance metrics such as recall, for scalable search testing in Elasticsearch.