Red Hat's OpenShift platform has long been a trusted foundation for enterprise Kubernetes workloads, and for years, its built-in Elasticsearch Operator has made log management simple. But all good things evolve: The OpenShift Elasticsearch Operator reached the end of its supported lifecycle with Red Hat OpenShift Container Platform (OCP) 4.13, and the Elasticsearch 6.x clusters it managed are long out of support. Working closely with Red Hat, we've put together this step-by-step guide to help you move from that legacy setup to Elastic Cloud on Kubernetes (ECK), the modern, full-featured operator maintained directly by Elastic. The migration path we've designed respects the OpenShift-native tooling you already rely on, keeps disruption to a minimum, and leaves you on a solid foundation for future upgrades to 8.x, 9.x, and beyond.
Why this matters
- Security and support: The last Elasticsearch 6.x patch release was on January 13, 2022. ECK lets you upgrade at your own pace, with a supported operator from the creators of Elasticsearch. Remaining on an old Elasticsearch version exposes you to supportability risks or well-known security issues.
- Features you’ve been missing: Autoscaling, data tiers, machine learning (ML) jobs, searchable snapshots. None of these are available in the legacy operator.
Future-proof operations: ECK ships day-and-date with every new Elastic release, so you’re never stuck waiting again.
High-level plan
| Phase | Goal | Outcome |
|---|---|---|
| 0 | Snapshot and sanity-check your 6.x cluster. | You have a backup in case you need it. |
| 1 | Install ECK 2.16.1 alongside the Red Hat operator. | Both operators coexist safely. |
| 2 | Spin up a fresh, production-ready ES 6.8.23 cluster managed by ECK. | Empty ECK-managed cluster. |
| 3 | Restore data into that new cluster. | All indices now live under ECK. |
| 4 | Point openshift-logging to the new service and retire the old operator. | Single source of truth. |
| 5 | Rolling-upgrade Elasticsearch to 7.17.28. | Latest long-term 7.x. |
| 6 | Upgrade ECK to 3.3.1. | Operator on current release. |
| 7 | Schedule your own jump to 8.x & 9.x. | You control the timing. |
| 8 | Clean up | Removing old operator |
Feel free to bookmark this list. Each milestone is small, reversible, and validated before you move on.
0. Preflight checks
A. Health first: Run /_cat/health and make sure you’re green.
B. Disk watermarks: Keep at least 20% free before starting a migration.
C. Final snapshot: S3, GCS, NFS: It doesn’t matter, as long as you can mount the same repo in the new cluster.
- If you don’t have object storage handy in your environment, you can use this solution-post by Red Hat to snapshot your data to local storage on the OpenShift cluster.
D. Review the documentation: Elastic provides thorough documentation for migrating data between Elasticsearch clusters.
1. Installing ECK 2.16.1 (your “bridge” operator)
ECK 2.16.1 is the last release that still accepts spec.version: 6.8.x, which makes it the ideal bridge between past and future Elasticsearch versions.
helm repo add elastic https://helm.elastic.co
helm repo update
oc create namespace elastic-system
helm install elastic-operator elastic/eck-operator --version=2.16.1 -n elastic-system --create-namespaceYou can keep the Red Hat operator in place; the two watch different Custom Resource Definitions (CRDs), so they won’t step on each other’s toes.
Keep in mind that with OpenShift, ECK might display some Transport Layer Security (TLS) errors in its logs as OpenShift tries to connect to its healthcheck webhook endpoint via HTTP, but ECK allows TLS communication only. This is a well-known issue and shouldn’t pose a problem.
You can refer further to Elastic documentation, in case you need to make a local namespaced installation.
2. Launching a 6.x cluster under ECK
Below is a starter Kubernetes manifest that balances resiliency (separate masters) with cost (three hot-tier data nodes). Swap storage class names, resources, and snapshot credentials to match your environment.
Note: The syntax used below is a bit different than what it would be for newer Elasticsearch versions on ECK.
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: es-logs
namespace: elastic # Create this namespace prior, or use another namespace
spec:
version: 6.8.23
nodeSets:
- name: hot
count: 3
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: gp3-csi # adjust if needed
resources:
requests:
storage: 100Gi # Storage may vary depending on
config:
node.master: true
node.data: true
node.ingest: true
node.attr.data: hot
cluster.routing.allocation.awareness.attributes: data
podTemplate:
spec:
containers:
- name: elasticsearch
resources:
requests:
memory: 16Gi
cpu: 2
limits:
memory: 16Gi
---
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana
namespace: elastic
spec:
version: 6.8.23
count: 1
elasticsearchRef:
name: es-logs
podTemplate:
spec:
containers:
- name: kibana
resources:
requests:
memory: 1Gi
cpu: 0.5
limits:
memory: 4GiDeploy it, watch pods come up, and you’re ready for data.
3. Moving the data
To move data from one Elasticsearch cluster to another, you can also further consult this guide in the Elastic documentation. For the purpose of this post, we’re assuming that snapshot and restore are used.
Snapshot and restore are quickest:
# on the old cluster, take a snapshot
PUT _snapshot/log-backups
{
"type": "s3",
"settings": { ... }
}
PUT _snapshot/log-backups/final-snap-2025-08-07
# on the new cluster (readonly!)
PUT _snapshot/log-backups
{
"type": "s3",
"settings": {
"readonly": true,
...
}
}
# Perform the restore operation
POST _snapshot/log-backups/final-snap-2025-08-07/_restoreCan’t share an object store? Use remote re-index (slower, but works everywhere; has drawbacks in terms of not migrating index templates, component templates, and more) or pump logs through a one-off Logstash job.
4. Configuring ClusterLogging operator
First, we’ll need to decommission our Red Hat operator–managed Elasticsearch cluster. We’ll modify our ClusterLogging like so:
oc edit clusterlogging instance -n openshift-logging
---------
logStore:
elasticsearch:
nodeCount: 0 # scale down node count, previously > 0
redundancyPolicy: ZeroRedundancy
type: elasticsearch
managementState: Managed # this needs to be kept, as it will manage the fluentd instance for us.
visualization:
kibana:
replicas: 0 # scale down kibana as well
type: kibanaThen we’ll define a ClusterLogForwarder to direct the logs from fluentd to our newly built Elasticsearch 6.x cluster managed by ECK. We’ll need to create a secret with the Elasticsearch credentials:
oc create secret generic eck-es-credentials \
-n openshift-logging \
--from-literal=username=elastic \
--from-literal=password=$(oc get secret es-logs-es-elastic-user -n elastic -o jsonpath='{.data.elastic}' | base64 -d)For configuring TLS (as recommended), you’ll need to create a ConfigMap for ClusterLogForwarder to trust the ECK ca certificates. Further guidance can be found here. We’ll run the command:
oc -n elastic get secret es-logs-es-http-certs-public \
-o go-template='{{index .data "tls.crt" | base64decode}}' > ca.crt
oc -n openshift-logging create configmap eck-es-ca \
--from-file=ca-bundle.crt=ca.crtTo create the certificate secret, and then we’ll reference it in the ClusterLogging CRD:
apiVersion: logging.openshift.io/v1
kind: ClusterLogForwarder
metadata:
name: instance
namespace: openshift-logging
spec:
outputs:
- name: eck-es
type: elasticsearch
url: https://es-logs-es-http.elastic.svc:9200
secret:
name: eck-es-credentials # this secret needs to be created first
tls:
# insecureSkipVerify: true # can be used for lab testing purposes
ca:
name: eck-es-ca
pipelines:
- name: send-to-eck
inputRefs:
- application
- infrastructure
- audit
outputRefs:
- eck-es⚠️ If you’re troubleshooting connectivity issues, you can temporarily set tls.insecureSkipVerify: true, but this shouldn’t be used long term.
Because we’re restoring legacy indices into a fresh ECK-managed cluster, OpenShift Logging will not automatically recreate the legacy index layout or aliases. You must ensure that write aliases exist and point to writable indices. In my case, I needed to verify that I have proper aliases, set up as:
- app-write
infra-writeaudit-write
Pointing to indices with dynamic mappings (not recommended) for minimizing errors and troubleshooting steps.
# Forward ES port to local machine
oc -n elastic port-forward svc/es-logs-es-http 9200:9200
PASS="$(oc -n elastic get secret es-logs-es-elastic-user -o jsonpath='{.data.elastic}' | base64 -d)"
# Make sure the write alias points to the correct backing index
curl -s -k -u "elastic:${PASS}" -XPOST "https://localhost:9200/_aliases" \
-H 'Content-Type: application/json' \
-d '{
"actions": [
{ "add": { "index": "infra-000002", "alias": "infra-write", "is_write_index": true } }
]
}'Repeat for app-write and audit-write with their respective backing indices.We should see data start flowing now toward our new ECK managed cluster.
5. Rolling upgrade to 7.17.29, and verify
Now you can finally leave 6.x behind.
A. Check _xpack/migration/deprecations?pretty using curl against Elasticsearch, to tackle deprecations. This API will return either warnings or critical things to attend to before you upgrade.
B. Patch the CRD to upgrade it to the latest 7.x version. I’m using 7.17.29.
oc -n elastic patch elasticsearch es-logs --type=merge -p '{"spec":{"version":"7.17.29"}}'C. ECK restarts nodes one at a time. Your cluster should be online throughout.
D. Give cluster tasks and shard recoveries time to settle before pressing on.
E. Don’t forget to upgrade Kibana in the same way.
oc -n elastic patch kibana kibana --type=merge -p '{"spec":{"version":"7.17.29"}}'Once complete, check your Elasticsearch version and Kibana version, as well as the health state:
oc -n elastic get elasticsearch es-logs
oc -n elastic get kibana kibana6. Operator upgrade: ECK 2.16.1 → 3.3.1
ECK upgrades are pleasantly boring:
helm upgrade elastic-operator elastic/eck-operator -n elastic-system --version 3.3.1Watch the operator pod roll. Your Elasticsearch cluster keeps running; only the controller restarts.
Verify that the upgrade is successful by looking at the operator logs and ensuring that no major errors appear:
oc logs -n elastic-system sts/elastic-operatorAnd then verifying the new version of the operator (will now be 3.3.1):
helm -n elastic-system list7. Your roadmap to 8.x and 9.x (when you’re ready)
You’re now on:
- ECK Operator: 3.3.1
- Elastic Stack: 7.17.29
That pair is fully supported and serves as the official launchpad for 8.x. It’s important to first go through the Elastic upgrade documentation.
We’ll again go through the procedure of checking for any hard-breaking changes between our 7.17.29 and the latest 8 version (8.19.9):
GET _migration/deprecations?prettyIt's important to look through the result of this query carefully and to go through necessary steps, like re-indexing indices and changing mappings, among others.
Once you’ve addressed all required changes from 7.17.29 to 8.x:
oc -n elastic patch elasticsearch es-logs --type=merge -p '{"spec":{"version":"8.19.9"}}'
oc -n elastic patch kibana kibana --type=merge -p '{"spec":{"version":"8.19.9"}}'ECK will handle the rest. Just remember to upgrade Beats, Logstash pipelines, and client libraries in lockstep to avoid wire-protocol surprises.
Repeat the process again to migrate to the latest 9.x version.
8. Cleanup
- Remove the Red Hat Elasticsearch operator.
Now that you’re no longer using the Red Hat Elasticsearch operator, you can remove it from your cluster. You can do that via the following steps:
A. In the OpenShift Console, go to Operators and then to Installed Operators.
B. In the Filter By Name field, enter “Elasticsearch” to find the installed Red Hat Elasticsearch operator.
C. On the Operator Details page, select Uninstall Operator from the Actions list.
D. On the Uninstall Operator? dialog box, select Uninstall. This removes the operator, the operator deployments, and the pods. After this step, the operator stops running and will no longer receive updates.
All of these steps can be found in this link from Red Hat OpenShift documentation.
Wrapping up
By installing ECK 2.16.1 as a bridge, snapshot-restoring into a new cluster, and stepping cleanly through 7.x before landing on ECK 3.3, you’ve transformed an aging, unsupported logging back end into a modern, secure, first-class Elastic deployment, without surprises or downtime.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
May 29, 2026
One API call per operation: how Elastic Cloud Hosted makes fleet-scale deployment management practical
Elastic Cloud Hosted adds five targeted APIs for upgrade, tier scaling, user settings, tags and snapshot repository linking, each replacing a multi-step deployment plan edit with a single focused call.
May 19, 2026
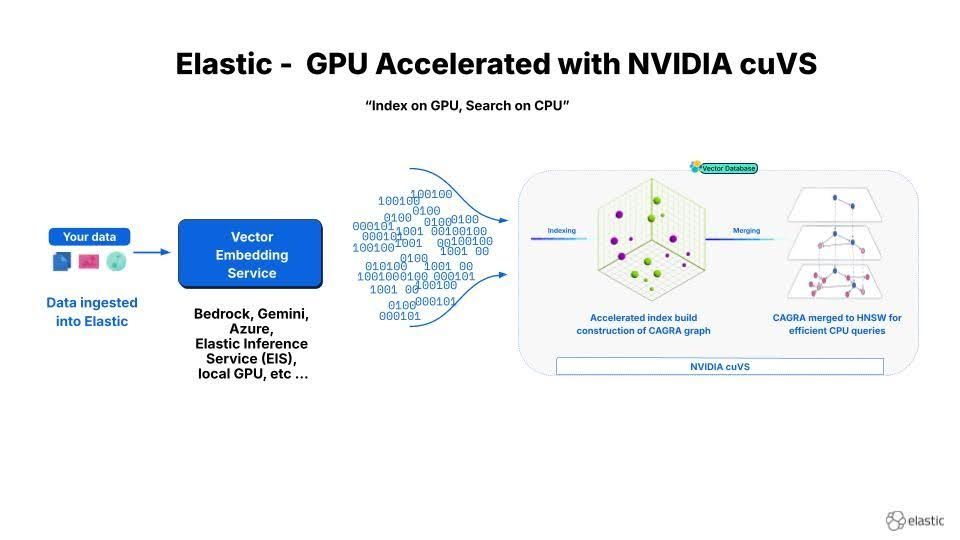
12x faster Elasticsearch vector indexing: deploying NVIDIA cuVS with GPU and CPU tiers
Two patterns for deploying NVIDIA cuVS GPU-accelerated HNSW indexing in Elasticsearch: combined build-and-serve nodes for small clusters and a dedicated GPU ingest tier with ILM handoff to CPU for production at scale.
May 18, 2026
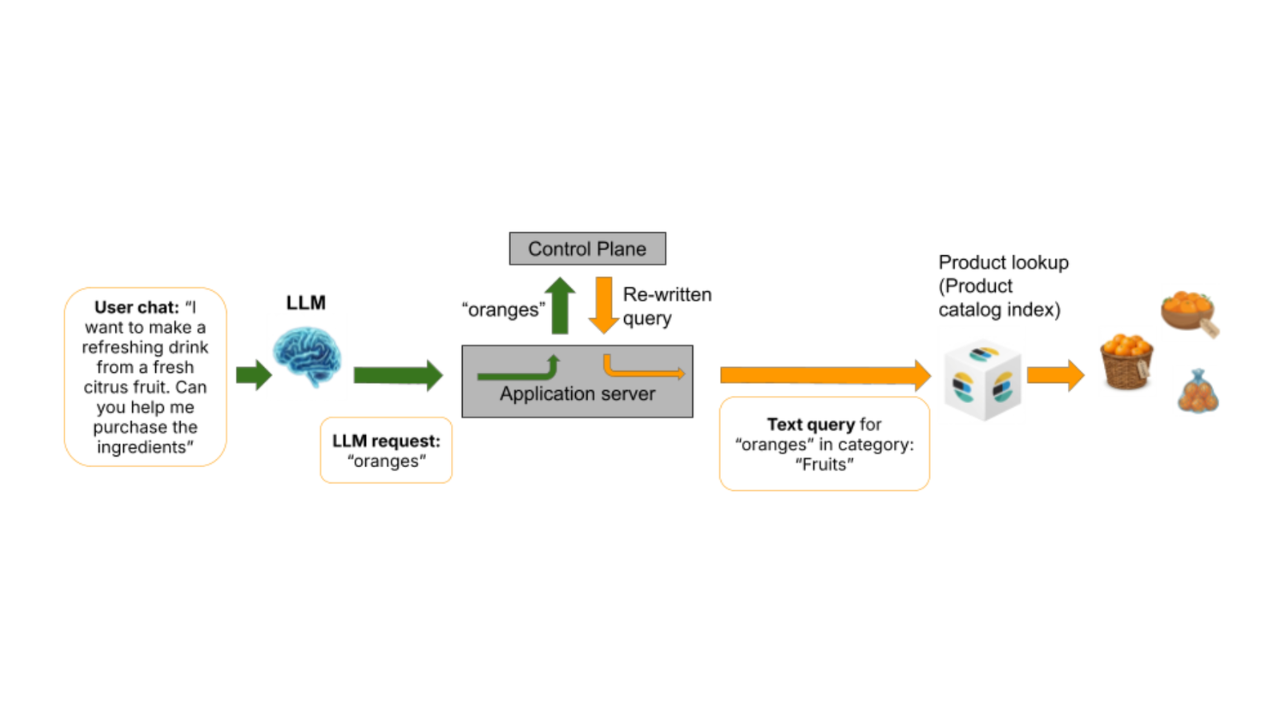
Agentic AI search with deterministic guardrails in Elasticsearch for safe query execution
Agentic AI search systems often fail when LLMs generate queries directly. Learn how deterministic guardrails and a control plane architecture enable safe, reliable, and governed query execution with Elasticsearch.

May 13, 2026
Ecommerce search optimization using margin and popularity boosting in Elasticsearch
Learn how to optimize ecommerce search using margin and popularity boosting. This blog explains how a governed control plane treats economic optimization in Elasticsearch.

May 11, 2026
Personalizing ecommerce search: Integrating purchase history and user cohorts
Learn how to create a personalized ecommerce search experience in Elasticsearch without breaking governance. This post explains how to boost products a shopper has purchased before and how to activate cohort-specific policies based on user profiles.