A2A and MCP: the code in action
This is the companion piece to the article “Creating an LLM Agent newsroom with A2A protocol and MCP in Elasticsearch!”, which explained the benefits of implementing both A2A and MCP architectures within the same agent to truly reap the unique benefits of both frameworks. A repository is available should you wish to run the demo on your own.
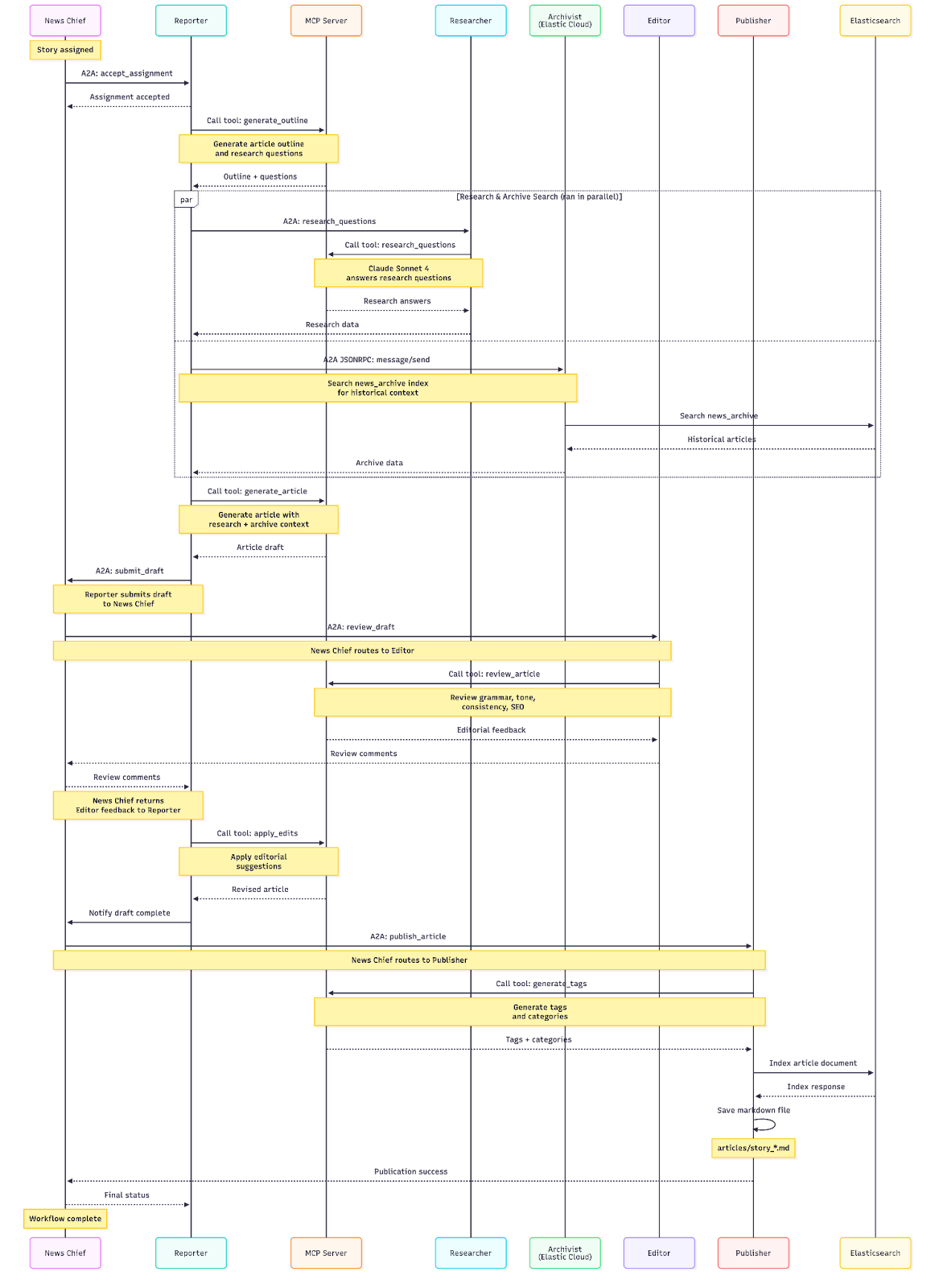
Let's walk through how our newsroom agents collaborate using both A2A and MCP to produce a news article. The accompanying repository to see the agents in action may be found here.
Step 1: Story assignment
The News Chief (acting as the client) assigns a story:
{
"message_type": "task_request",
"sender": "news_chief",
"receiver": "reporter_agent",
"payload": {
"task_id": "story_renewable_energy_2024",
"assignment": {
"topic": "Renewable Energy Adoption in Europe",
"angle": "Policy changes driving solar and wind expansion",
"target_length": 1200,
"deadline": "2025-09-30T18:00:00Z"
}
}
}Step 2: Reporter requests research
The Reporter Agent recognizes it needs background information and delegates to the Researcher Agent via A2A:
{
"message_type": "task_request",
"sender": "reporter_agent",
"receiver": "researcher_agent",
"payload": {
"task_id": "research_eu_renewable_2024",
"parent_task_id": "story_renewable_energy_2024",
"capability": "fact_gathering",
"parameters": {
"queries": [
"EU renewable energy capacity 2024",
"Solar installations growth Europe",
"Wind energy policy changes 2024"
],
"depth": "comprehensive"
}
}
}Step 3: Reporter requests historical context from Archive Agent
The Reporter Agent recognizes that historical context would strengthen the story. It delegates to the Archive Agent (powered by Elastic's A2A Agent) via A2A to search the newsroom's Elasticsearch-powered article archive:
{
"message_type": "task_request",
"sender": "reporter_agent",
"receiver": "archive_agent",
"payload": {
"task_id": "archive_search_renewable_2024",
"parent_task_id": "story_renewable_energy_2024",
"capability": "search_archive",
"parameters": {
"query": "European renewable energy policy changes and adoption trends over past 5 years",
"focus_areas": ["solar", "wind", "policy", "Germany", "France"],
"time_range": "2019-2024",
"result_count": 10
}
}
}Step 4: Archive Agent uses Elastic A2A Agent with MCP
The Archive Agent uses Elastic's A2A Agent, which in turn uses MCP to access Elasticsearch tools. This demonstrates the hybrid architecture where A2A enables agent collaboration while MCP provides tool access:
# Archive Agent using Elastic A2A Agent
async def search_historical_articles(self, query_params):
# The Archive Agent sends a request to Elastic's A2A Agent
elastic_response = await self.a2a_client.send_request(
agent="elastic_agent",
capability="search_and_analyze",
parameters={
"natural_language_query": query_params["query"],
"index_pattern": "newsroom-articles-*",
"filters": {
"topics": query_params["focus_areas"],
"date_range": query_params["time_range"]
},
"analysis_type": "trend_analysis"
}
)
# Elastic's A2A Agent internally uses MCP tools:
# - platform.core.search (to find relevant articles)
# - platform.core.generate_esql (to analyze trends)
# - platform.core.index_explorer (to identify relevant indices)
return elastic_responseThe Archive Agent receives comprehensive historical data from Elastic's A2A Agent and returns it to the Reporter:
{
"message_type": "task_response",
"sender": "archive_agent",
"receiver": "reporter_agent",
"payload": {
"task_id": "archive_search_renewable_2024",
"status": "completed",
"archive_data": {
"historical_articles": [
{
"title": "Germany's Energiewende: Five Years of Solar Growth",
"published": "2022-06-15",
"key_points": [
"Germany added 7 GW annually 2020-2022",
"Policy subsidies drove 60% of growth"
],
"relevance_score": 0.94
},
{
"title": "France Balances Nuclear and Renewables",
"published": "2023-03-20",
"key_points": [
"France increased renewable target to 40% by 2030",
"Solar capacity doubled 2021-2023"
],
"relevance_score": 0.89
}
],
"trend_analysis": {
"coverage_frequency": "EU renewable stories increased 150% since 2019",
"emerging_themes": ["policy incentives", "grid modernization", "battery storage"],
"coverage_gaps": ["Small member states", "offshore wind permitting"]
},
"total_articles_found": 47,
"search_confidence": 0.91
}
}
}This step demonstrates how Elastic's A2A Agent integrates into the newsroom workflow. The Archive Agent (a newsroom-specific agent) coordinates with Elastic's A2A Agent (a third-party specialist) to leverage Elasticsearch's powerful search and analytics capabilities. Elastic's agent uses MCP internally to access Elasticsearch tools, showing the clean separation between agent coordination (A2A) and tool access (MCP).
Step 5: Researcher uses MCP servers
The Researcher Agent accesses multiple MCP servers to gather information:
# Researcher Agent using MCP to access tools
async def gather_facts(self, queries):
results = []
# Use News API MCP Server
news_data = await self.mcp_client.invoke_tool(
server="news_api_mcp",
tool="search_articles",
parameters={
"query": queries[0],
"date_range": "2024-01-01 to 2024-09-30",
"sources": ["reuters", "bloomberg", "euractiv"]
}
)
# Use Statistics MCP Server
stats_data = await self.mcp_client.invoke_tool(
server="eurostat_mcp",
tool="get_energy_statistics",
parameters={
"metrics": ["solar_capacity_mw", "wind_capacity_mw"],
"countries": ["EU27"],
"year": 2024
}
)
# Use Fact-Checking MCP Server
verified_facts = await self.mcp_client.invoke_tool(
server="factcheck_mcp",
tool="verify_claims",
parameters={
"claims": [
"EU solar capacity increased 40% in 2024",
"Germany leads in wind installations"
]
}
)
return self._synthesize_research(news_data, stats_data, verified_facts)Step 6: Researcher returns data to Reporter
The Researcher Agent sends comprehensive research back via A2A:
{
"message_type": "task_response",
"sender": "researcher_agent",
"receiver": "reporter_agent",
"payload": {
"task_id": "research_eu_renewable_2024",
"status": "completed",
"research_data": {
"key_facts": [
{
"claim": "EU solar capacity reached 260 GW in 2024",
"source": "Eurostat Q3 2024 Report",
"confidence": 0.95,
"verified": true
},
{
"claim": "Germany installed 12 GW of wind capacity in 2024",
"source": "German Federal Network Agency",
"confidence": 0.92,
"verified": true
}
],
"statistics": {
"solar_growth_rate": "35%",
"wind_growth_rate": "28%"
},
"sources_count": 15
}
}
}Step 7: Reporter writes article
The Reporter Agent uses the research data and its own LLM capabilities to write the article. During writing, the Reporter uses the MCP servers for style and templates:
# Reporter Agent writing with MCP assistance
async def write_article(self, research_data, assignment):
# Get style guidelines via MCP
style_guide = await self.mcp_client.get_resource(
server="newsroom_mcp",
resource="style://editorial/ap_style_guide"
)
# Get article template via MCP
template = await self.mcp_client.get_resource(
server="newsroom_mcp",
resource="template://articles/news_story"
)
# Generate article using LLM + research + style
draft = await self.llm.generate(
prompt=f"""
Write a news article following these guidelines:
{style_guide}
Using this template:
{template}
Based on this research:
{research_data}
Assignment: {assignment}
"""
)
# Self-evaluate confidence in claims
confidence_check = await self._evaluate_confidence(draft)
return draft, confidence_checkStep 8: low confidence triggers Re-Research
The Reporter Agent evaluates its draft and finds that one claim has low confidence. It sends another request to the Researcher Agent:
{
"message_type": "collaboration_request",
"sender": "reporter_agent",
"receiver": "researcher_agent",
"payload": {
"request_type": "fact_verification",
"claims": [
{
"text": "France's nuclear phase-down contributed to 15% increase in renewable capacity",
"context": "Discussing policy drivers for renewable growth",
"current_confidence": 0.45,
"required_confidence": 0.80
}
],
"urgency": "high"
}
}The Researcher verifies the claim using fact-checking MCP servers and returns updated information:
{
"message_type": "collaboration_response",
"sender": "researcher_agent",
"receiver": "reporter_agent",
"payload": {
"verified_claims": [
{
"original_claim": "France's nuclear phase-down contributed to 15% increase...",
"verified_claim": "France's renewable capacity increased 18% in 2024, partially offsetting reduced nuclear output",
"confidence": 0.88,
"corrections": "Percentage was 18%, not 15%; nuclear phase-down is gradual, not primary driver",
"sources": ["RTE France", "French Energy Ministry Report 2024"]
}
]
}
}Step 9: Reporter revises and submits to Editor
The Reporter incorporates the verified facts and sends the completed draft to the Editor Agent via A2A:
{
"message_type": "task_request",
"sender": "reporter_agent",
"receiver": "editor_agent",
"payload": {
"task_id": "edit_renewable_story",
"parent_task_id": "story_renewable_energy_2024",
"content": {
"headline": "Europe's Renewable Revolution: Solar and Wind Surge 30% in 2024",
"body": "[Full article text...]",
"word_count": 1185,
"sources": [/* array of sources */]
},
"editing_requirements": {
"check_style": true,
"check_facts": true,
"check_seo": true
}
}
}Step 10: Editor reviews using MCP tools
The Editor Agent uses multiple MCP servers to review the article:
# Editor Agent using MCP for quality checks
async def review_article(self, content):
# Grammar and style check
grammar_issues = await self.mcp_client.invoke_tool(
server="grammarly_mcp",
tool="check_document",
parameters={"text": content["body"]}
)
# SEO optimization check
seo_analysis = await self.mcp_client.invoke_tool(
server="seo_mcp",
tool="analyze_content",
parameters={
"headline": content["headline"],
"body": content["body"],
"target_keywords": ["renewable energy", "Europe", "solar", "wind"]
}
)
# Plagiarism check
originality = await self.mcp_client.invoke_tool(
server="plagiarism_mcp",
tool="check_originality",
parameters={"text": content["body"]}
)
# Generate editorial feedback
feedback = await self._generate_feedback(
grammar_issues,
seo_analysis,
originality
)
return feedbackThe Editor approves the article and sends it forward:
{
"message_type": "task_response",
"sender": "editor_agent",
"receiver": "reporter_agent",
"payload": {
"status": "approved",
"quality_score": 9.2,
"minor_edits": [
"Changed 'surge' to 'increased' in paragraph 3 for AP style consistency",
"Added Oxford comma in list of countries"
],
"approved_content": "[Final edited article]"
}
}Step 11: Publisher publishes via CI/CD
Finally, the Printer Agent publishes the approved article using the MCP servers for the CMS and CI/CD pipeline:
# Publisher Agent publishing via MCP
async def publish_article(self, content, metadata):
# Upload to CMS via MCP
cms_result = await self.mcp_client.invoke_tool(
server="wordpress_mcp",
tool="create_post",
parameters={
"title": content["headline"],
"body": content["body"],
"status": "draft",
"categories": metadata["categories"],
"tags": metadata["tags"],
"featured_image_url": metadata["image_url"]
}
)
post_id = cms_result["post_id"]
# Trigger CI/CD deployment via MCP
deploy_result = await self.mcp_client.invoke_tool(
server="cicd_mcp",
tool="trigger_deployment",
parameters={
"pipeline": "publish_article",
"environment": "production",
"post_id": post_id,
"schedule": "immediate"
}
)
# Track analytics
await self.mcp_client.invoke_tool(
server="analytics_mcp",
tool="register_publication",
parameters={
"post_id": post_id,
"publish_time": datetime.now().isoformat(),
"story_id": metadata["story_id"]
}
)
return {
"status": "published",
"post_id": post_id,
"url": f"https://newsroom.example.com/articles/{post_id}",
"deployment_id": deploy_result["deployment_id"]
}The Publisher confirms publication via A2A:
{
"message_type": "task_complete",
"sender": "printer_agent",
"receiver": "news_chief",
"payload": {
"task_id": "story_renewable_energy_2024",
"status": "published",
"publication": {
"url": "https://newsroom.example.com/articles/renewable-europe-2024",
"published_at": "2025-09-30T17:45:00Z",
"post_id": "12345"
},
"workflow_metrics": {
"total_time_minutes": 45,
"agents_involved": ["reporter", "researcher", "archive", "editor", "printer"],
"iterations": 2,
"mcp_calls": 12
}
}
}Here is the complete sequence of the A2A workflow in the accompanying repository using the same Agents described above.
| # | From | To | Action | Protocol | Description |
|---|---|---|---|---|---|
| 1 | User | News Chief | Assign Story | HTTP POST | User submits story topic and angle |
| 2 | News Chief | Internal | Create Story | - | Creates story record with unique ID |
| 3 | News Chief | Reporter | Delegate Assignment | A2A | Sends story assignment via A2A protocol |
| 4 | Reporter | Internal | Accept Assignment | - | Stores assignment internally |
| 5 | Reporter | MCP Server | Generate Outline | MCP/HTTP | Creates article outline and research questions |
| 6a | Reporter | Researcher | Request Research | A2A | Sends questions (parallel with 6b) |
| 6b | Reporter | Archivist | Search Archive | A2A JSONRPC | Searches historical articles (parallel with 6a) |
| 7 | Researcher | MCP Server | Research Questions | MCP/HTTP | Uses Anthropic via MCP to answer questions |
| 8 | Researcher | Reporter | Return Research | A2A | Returns research answers |
| 9 | Archivist | Elasticsearch | Search Index | ES REST API | Queries news_archive index |
| 10 | Archivist | Reporter | Return Archive | A2A JSONRPC | Returns historical search results |
| 11 | Reporter | MCP Server | Generate Article | MCP/HTTP | Creates article with research/archive context |
| 12 | Reporter | Internal | Store Draft | - | Saves draft internally |
| 13 | Reporter | News Chief | Submit Draft | A2A | Submits completed draft |
| 14 | News Chief | Internal | Update Story | - | Stores draft, updates status to "draft_submitted" |
| 15 | News Chief | Editor | Review Draft | A2A | Auto-routes to Editor for review |
| 16 | Editor | MCP Server | Review Article | MCP/HTTP | Analyzes content using Anthropic via MCP |
| 17 | Editor | News Chief | Return Review | A2A | Sends editorial feedback and suggestions |
| 18 | News Chief | Internal | Store Review | - | Stores editor feedback |
| 19 | News Chief | Reporter | Apply Edits | A2A | Routes review feedback to Reporter |
| 20 | Reporter | MCP Server | Apply Edits | MCP/HTTP | Revises article based on feedback |
| 21 | Reporter | Internal | Update Draft | - | Updates draft with revisions |
| 22 | Reporter | News Chief | Return Revised | A2A | Returns revised article |
| 23 | News Chief | Internal | Update Story | - | Stores revised draft, status to "revised" |
| 24 | News Chief | Publisher | Publish Article | A2A | Auto-routes to Publisher |
| 25 | Publisher | MCP Server | Generate Tags | MCP/HTTP | Creates tags and categories |
| 26 | Publisher | Elasticsearch | Index Article | ES REST API | Indexes article to news_archive index |
| 27 | Publisher | Filesystem | Save Markdown | File I/O | Saves article as .md file in /articles |
| 28 | Publisher | News Chief | Confirm Publication | A2A | Returns success status |
| 29 | News Chief | Internal | Update Story | - | Updates story status to "published" |
Conclusion
Both A2A and MCP have important roles to play in the modern augmented-LLM infrastructure paradigm. A2A offers flexibility for complex multi-agent systems but potentially less portability and higher operational complexity. MCP offers a standardized approach for tool integration that's simpler to implement and maintain, though it's not designed to handle multi-agent orchestration.
The choice isn't binary. As demonstrated through our newsroom example, the most sophisticated and effective LLM-backed systems often combine both approaches: agents coordinate and specialize through A2A protocols while accessing their tools and resources through MCP servers. This hybrid architecture provides the organizational benefits of multi-agent systems alongside the standardization and ecosystem advantages of MCP. This suggests that there may not need to be a choice at all: simply use both as a standard approach
It's up to you as a developer or architect to test and determine the best mixture of both solutions to create the right outcome for your specific use case. Understanding the strengths, limitations, and appropriate applications of each approach will enable you to build more effective, maintainable, and scalable AI systems.
Whether you're building a digital newsroom, a customer service platform, a research assistant, or any other LLM-powered application, carefully considering your coordination needs (A2A) and tool access requirements (MCP) will set you on the path to success.
Additional resources
- Elasticsearch Agent Builder: https://www.elastic.co/docs/solutions/search/elastic-agent-builder
- A2A Specification: https://a2a-protocol.org/latest/specification/
- A2A and MCP Integration: https://a2a-protocol.org/latest/topics/a2a-and-mcp/
- Model Context Protocol: https://modelcontextprotocol.io
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

March 23, 2026
Using Elasticsearch Inference API along with Hugging Face models
Learn how to connect Elasticsearch to Hugging Face models using inference endpoints, and build a multilingual blog recommendation system with semantic search and chat completions.
March 27, 2026
Creating an Elasticsearch MCP server with TypeScript
Learn how to create an Elasticsearch MCP server with TypeScript and Claude Desktop.
March 17, 2026
The Gemini CLI extension for Elasticsearch with tools and skills
Introducing Elastic’s extension for Google's Gemini CLI to search, retrieve, and analyze Elasticsearch data in developer and agentic workflows.

March 16, 2026
Agent Skills for Elastic: Turn your AI agent into an Elastic expert
Give your AI coding agent the knowledge to query, visualize, secure, and automate with Elastic Agent Skills.
March 18, 2026
AI agent memory: Creating smart agents with Elasticsearch managed memory
Learn how to create smarter and more efficient AI agents by managing memory using Elasticsearch.