In this article, we’ll explore how to combine LangGraph and Elasticsearch to build a human-in-the-loop (HITL) system. This approach allows AI systems to involve users directly in the decision-making process, making interactions more reliable and context-aware. We’ll implement a practical example using a context-driven scenario to demonstrate how LangGraph workflows can integrate with Elasticsearch to retrieve data, handle user input, and produce refined results.
Requirements
- NodeJS version 18 or newer
- OpenAI API Key
- Elasticsearch 8.x+ deployment
Why use LangGraph for production HITL systems
In a previous article, we presented LangGraph and its benefits for building a retrieval-augmented generation (RAG) system using large language models (LLMs) and conditional edges to automatically make decisions and display results. Sometimes we don’t want the system to act autonomously end to end, but we want users to select options and make decisions within the execution loop. This concept is called human in the loop.
Human in the loop
HITL is an AI concept that allows a real person to interact with AI systems to provide more context, evaluate responses, edit responses, ask for more information, and perform other tasks. This is very useful in low-error-tolerance scenarios, such as compliance, decision-making, and content generation, helping improve the reliability of LLM outputs.
It's important to note that the primary purpose of HITL in agentic systems is validation, not blind trust in the agent's approach. HITL interventions should be reactive and triggered only when the system detects missing or ambiguous information. This ensures human involvement remains meaningful and adds value, rather than becoming a mandatory checkpoint that interrupts every workflow unnecessarily.
A common example is when your coding assistant asks you for permission to execute a certain command on the terminal or shows you the step-by-step thinking process for you to approve before starting coding.
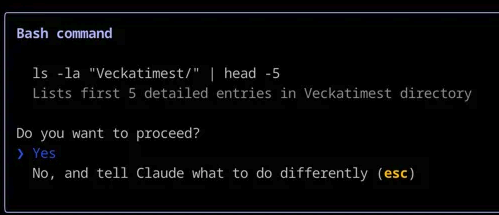
Claude Code using human in the loop to ask you for confirmation before executing a Bash command.
Elasticsearch and LangGraph: How they interact
LangChain allows us to use Elasticsearch as a vector store and to perform queries within LangGraph applications, which is useful to execute full-text or semantic searches, while LangGraph is used to define the specific workflow, tools, and interactions. It also adds HITL as an additional interaction layer with the user.
Practical implementation: Human in the loop
Let’s imagine a case where a lawyer has a question about a case he recently took on. Without the right tools, he would need to manually search through legal articles and precedents, read them in full, and then interpret how they apply to his situation. With LangGraph and Elasticsearch, however, we can build a system that searches a database of legal precedents and generates a case analysis that incorporates the specific details and context provided by the lawyer. You can find the full implementation of this use case in the following repository.
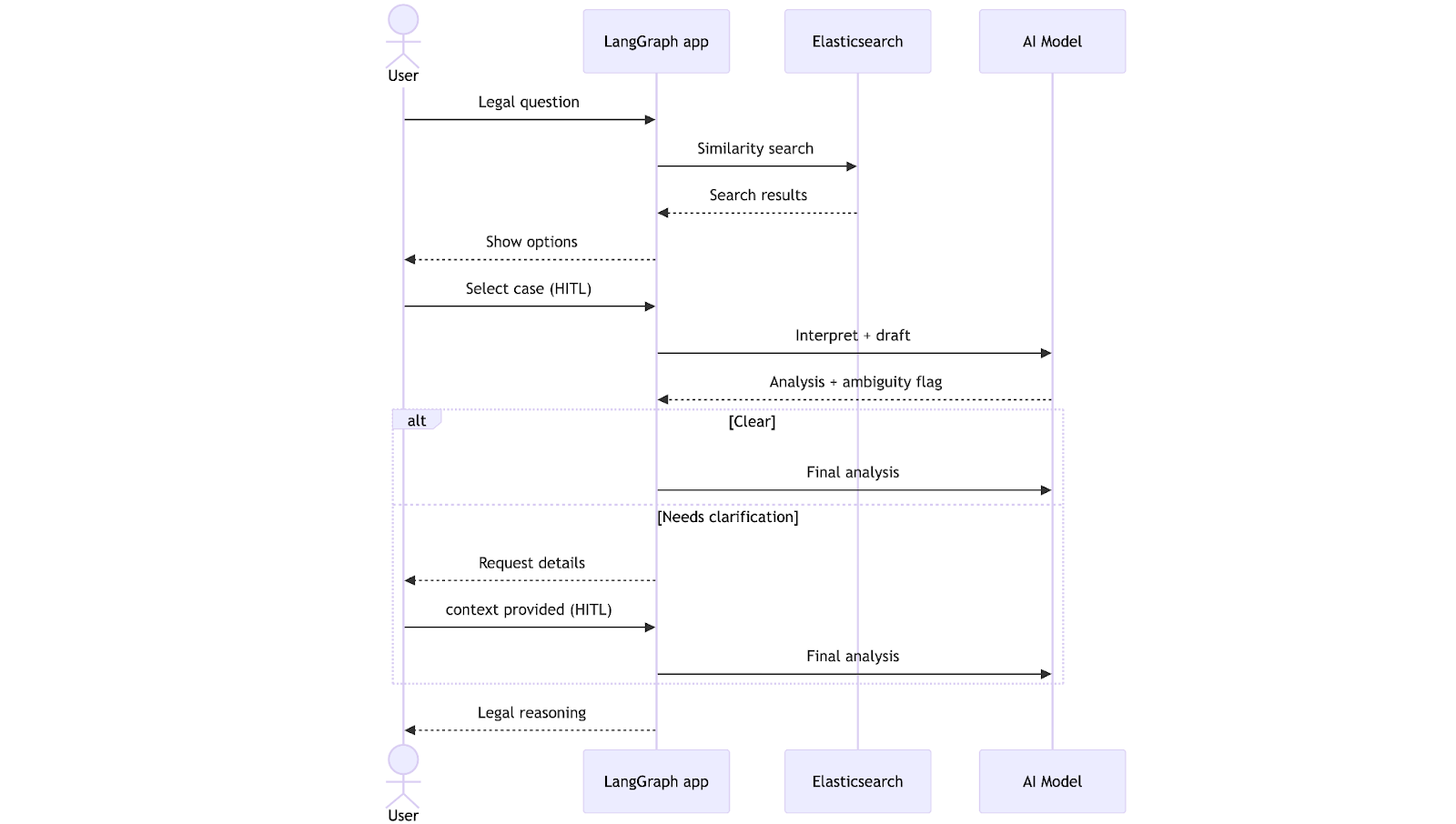
The workflow begins when the lawyer submits a legal question. The system performs a vector search in Elasticsearch, retrieves the most relevant precedents, and presents them for the lawyer to choose from, using natural language. After the selection, the LLM generates a draft analysis and checks whether the information is complete. At this point, the workflow can follow two paths: If everything is clear, it proceeds directly to generate a final analysis; if not, it pauses to request clarification from the lawyer. Once the missing context is provided, the system completes the analysis and returns it, taking into consideration the clarifications.
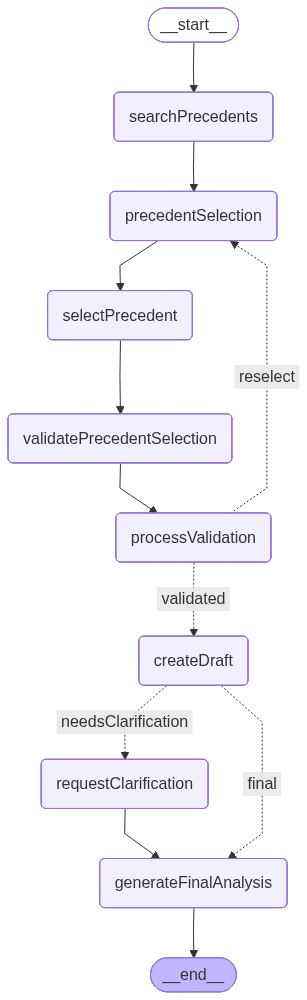
The following is a graph drawn by LangGraph showing how the app will look at the end of the development. Each node represents a tool or functionality:
Dataset
Here’s the dataset that will be used for this example. This dataset contains a collection of legal precedents, each describing a case involving service delays, the court’s reasoning, and the final outcome.
[
{
"pageContent": "Legal precedent: Case B - Service delay not considered breach. A consulting contract used term 'timely delivery' without specific dates. A three-week delay occurred but contract lacked explicit schedule. Court ruled no breach as parties had not defined concrete timeline and delay did not cause demonstrable harm.",
"metadata": {
"caseId": "CASE-B-2022",
"contractType": "consulting agreement",
"delayPeriod": "three weeks",
"outcome": "no breach found",
"reasoning": "no explicit deadline defined, no demonstrable harm",
"keyTerms": "timely delivery, open terms, schedule definition",
"title": "Case B: Delay Without Explicit Schedule"
}
},
...
]Ingestion and index setup
The index setup and data ingestion logic are defined in the dataIngestion.ts file, where we declare functions to handle the index creation. This setup is compatible with the LangChain vector store interface for Elasticsearch.
Note: The mapping setup is also included in the dataIngestion.ts file.
Install packages and set up environment variables
Let's initialize a Node.js project with default settings:
npm init -yNow let's install all required dependencies:
- @elastic/elasticsearch: Elasticsearch client for Node.js. Used to connect, create indices, and run queries.
- @langchain/community: Provides integrations for community-supported tools, including the ElasticVectorSearch store.
- @langchain/core: Core building blocks of LangChain, such as chains, prompts, and utilities.
- @langchain/langgraph: Adds graph-based orchestration, allowing workflows with nodes, edges, and state management.
- @langchain/openai: Provides access to OpenAI models (LLMs and embeddings) through LangChain.
- dotenv: Loads environment variables from an .env file into process.env.
- tsx: Is a useful tool to execute typescript code.
Run the following command in the console to install all of them:
npm install @elastic/elasticsearch @langchain/community @langchain/core @langchain/langgraph @langchain/openai dotenv --legacy-peer-deps && npm install --save-dev tsxCreate an .env file to set up the environment variables:
ELASTICSEARCH_ENDPOINT=
ELASTICSEARCH_API_KEY=
OPENAI_API_KEY=We’ll use TypeScript to write the code because it provides a layer of type safety and a better developer experience. Create a TypeScript file named main.ts, and insert the next section's code.
Package imports
In the main.ts file, we start by importing the required modules and initializing the environment variable configuration. This includes the core LangGraph components, the OpenAI model integrations, and the Elasticsearch client.
We also import the following from the dataIngestion.ts file:
ingestData: A function that creates the index and ingests the data.- Document and DocumentMetadata: Interfaces that define the dataset document structure.
Elasticsearch vector store client, embeddings client, and OpenAI client
This code will initialize the vector store, the embeddings client, and one OpenAI client:
const VECTOR_INDEX = "legal-precedents";
const llm = new ChatOpenAI({ model: "gpt-4o-mini" });
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
});
const esClient = new Client({
node: process.env.ELASTICSEARCH_ENDPOINT,
auth: {
apiKey: process.env.ELASTICSEARCH_API_KEY ?? "",
},
});
const vectorStore = new ElasticVectorSearch(embeddings, {
client: esClient,
indexName: VECTOR_INDEX,
});Application workflow state schema will help in the communication between nodes:
const LegalResearchState = Annotation.Root({
query: Annotation<string>(),
precedents: Annotation<Document[]>(),
userChoice: Annotation<string>(),
selectedPrecedent: Annotation<Document | null>(),
validation: Annotation<string>(),
draftAnalysis: Annotation<string>(),
ambiguityDetected: Annotation<boolean>(),
userClarification: Annotation<string>(),
finalAnalysis: Annotation<string>(),
});In the state object, we’ll pass the following through the nodes: the user’s query, the concepts extracted from it, the legal precedents retrieved, and any ambiguity detected. The state also tracks the precedent selected by the user, the draft analysis generated along the way, and the final analysis once all clarifications are completed.
Nodes
searchPrecedents: This node performs a similarity search in the Elasticsearch vector store based on the user’s input. It retrieves up to five matching documents and prints them so they can be reviewed by the user:
async function searchPrecedents(state: typeof LegalResearchState.State) {
console.log(
"📚 Searching for relevant legal precedents with query:\n",
state.query
);
const results = await vectorStore.similaritySearch(state.query, 5);
const precedents = results.map((d) => d as Document);
console.log(`Found ${precedents.length} relevant precedents:\n`);
for (let i = 0; i < precedents.length; i++) {
const p = precedents[i];
const m = p.metadata;
console.log(
`${i + 1}. ${m.title} (${m.caseId})\n` +
` Type: ${m.contractType}\n` +
` Outcome: ${m.outcome}\n` +
` Key reasoning: ${m.reasoning}\n` +
` Delay period: ${m.delayPeriod}\n`
);
}
return { precedents };
}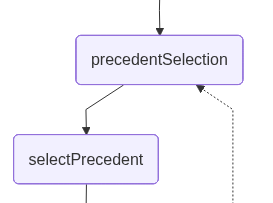
precedentSelection: This node allows the user to select, using natural language, the use case retrieved by the proximity search that best matches the question. At this point, the application interrupts the workflow and waits for user input:
function precedentSelection(state: typeof LegalResearchState.State) {
console.log("\n⚖️ HITL #1: Human input needed\n");
const result = interrupt({
question: "👨⚖️ Which precedent is most similar to your case? ",
});
return { userChoice: result as string };
}selectPrecedent: This node sends the user input, along with the retrieved documents, to be interpreted so that one of them can be selected. The LLM performs this task by returning a number that represents the document it infers from the user’s natural-language input:
async function selectPrecedent(state: typeof LegalResearchState.State) {
const precedents = state.precedents || [];
const userInput = state.userChoice || "";
const precedentsList = precedents
.map((p, i) => {
const m = p.metadata;
return `${i + 1}. ${m.caseId}: ${m.title} - ${m.outcome}`;
})
.join("\n");
const structuredLlm = llm.withStructuredOutput({
name: "precedent_selection",
schema: {
type: "object",
properties: {
selected_number: {
type: "number",
description:
"The precedent number selected by the lawyer (1-based index)",
minimum: 1,
maximum: precedents.length,
},
},
required: ["selected_number"],
},
});
const prompt = `
The lawyer said: "${userInput}"
Available precedents:
${precedentsList}
Which precedent number (1-${precedents.length}) matches their selection?
`;
const response = await structuredLlm.invoke([
{
role: "system",
content:
"You are an assistant that interprets lawyer's selection and returns the corresponding precedent number.",
},
{ role: "user", content: prompt },
]);
const selectedIndex = response.selected_number - 1;
const selectedPrecedent = precedents[selectedIndex] || precedents[0];
console.log(`✅ Selected: ${selectedPrecedent.metadata.title}\n`);
return { selectedPrecedent };
}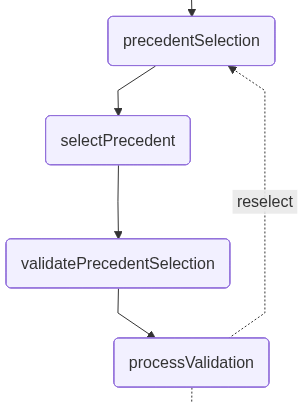
validatePrecedentSelectionThis node introduces an explicit validation step (yes/no) to confirm that the precedent inferred by the system is indeed the one the lawyer intends to use. This step acts as a safeguard against misinterpretation of the user’s intent, ensuring that downstream legal analysis is based on the correct case:
function validatePrecedentSelection(state: typeof LegalResearchState.State) {
const precedent = state.selectedPrecedent;
if (!precedent) return {};
const m = precedent.metadata;
console.log("\n⚖️ HITL #1.5: Validation needed\n");
console.log(
`Selected precedent: ${m.title} (${m.caseId})\n` +
`Type: ${m.contractType}\n` +
`Outcome: ${m.outcome}\n`
);
const result = interrupt({
question: "👨⚖️ Is this the correct precedent? (yes/no): ",
});
const validation =
typeof result === "string" ? result : (result as any)?.value || "";
return { validation };
}processValidation: This node processes the lawyer’s confirmation response (yes/no) from the previous HITL step and determines the next path in the workflow. It interprets the user input as an explicit approval or rejection of the selected precedent.
If the precedent isn’t confirmed, the node clears the current selection and redirects the graph back to the precedentSelection phase, allowing the user to choose again. If the precedent is confirmed, the workflow continues without modification:
function processValidation(state: typeof LegalResearchState.State) {
const userInput = (state.validation || "").toLowerCase().trim();
const isValid = userInput === "yes" || userInput === "y";
if (!isValid) {
console.log("❌ Precedent not confirmed. Returning to selection...\n");
return { selectedPrecedent: null, userChoice: "" };
}
console.log("✅ Precedent confirmed.\n");
return {};
}
createDraft: This node generates the initial legal analysis based on the precedent selected by the user. It uses an LLM to evaluate how the chosen precedent applies to the lawyer’s question and determines whether the system has enough information to proceed.
If the precedent can be applied directly, the node produces a draft analysis and, taking the right path, jumps to the final node. If the LLM detects ambiguities, such as undefined contract terms, missing timeline details, or unclear conditions, it returns a flag indicating that clarification is required, along with a list of the specific pieces of information that must be provided. In that case, the ambiguity triggers the left path of the graph:
async function createDraft(state: typeof LegalResearchState.State) {
console.log("📝 Drafting initial legal analysis...\n");
const precedent = state.selectedPrecedent;
if (!precedent) return { draftAnalysis: "" };
const m = precedent.metadata;
const structuredLlm = llm.withStructuredOutput({
name: "draft_analysis",
schema: {
type: "object",
properties: {
needs_clarification: {
type: "boolean",
description:
"Whether the analysis requires clarification about contract terms or context",
},
analysis_text: {
type: "string",
description: "The draft legal analysis or the ambiguity explanation",
},
missing_information: {
type: "array",
items: { type: "string" },
description:
"List of specific information needed if clarification is required (empty if no clarification needed)",
},
},
required: ["needs_clarification", "analysis_text", "missing_information"],
},
});
const prompt = `
Based on this precedent:
Case: ${m.title}
Outcome: ${m.outcome}
Reasoning: ${m.reasoning}
Key terms: ${m.keyTerms}
And the lawyer's question: "${state.query}"
Draft a legal analysis applying this precedent to the question.
If you need more context about the specific contract terms, timeline details,
or other critical information to provide accurate analysis, set needs_clarification
to true and list what information is missing.
Otherwise, provide the legal analysis directly.
`;
const response = await structuredLlm.invoke([
{
role: "system",
content:
"You are a legal research assistant that analyzes cases and identifies when additional context is needed.",
},
{ role: "user", content: prompt },
]);
let displayText: string;
if (response.needs_clarification) {
const missingInfoList = response.missing_information
.map((info: string, i: number) => `${i + 1}. ${info}`)
.join("\n");
displayText = `AMBIGUITY DETECTED:\n${response.analysis_text}\n\nMissing information:\n${missingInfoList}`;
} else {
displayText = `ANALYSIS:\n${response.analysis_text}`;
}
console.log(displayText + "\n");
return {
draftAnalysis: displayText,
ambiguityDetected: response.needs_clarification,
};
}The two paths that the graph can take look like this:
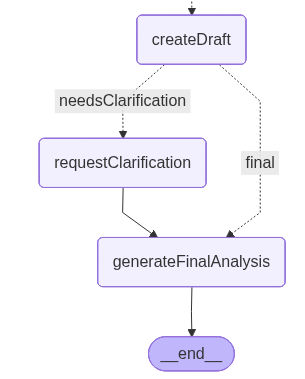
The left path includes an additional node that handles the clarification.
requestClarification: This node triggers the second HITL step when the system identifies that the draft analysis lacks essential context. The workflow is interrupted, and the user is asked to clarify the missing contract details detected by the previous node:
function requestClarification(state: typeof LegalResearchState.State) {
console.log("\n⚖️ HITL #2: Additional context needed\n");
const userClarification = interrupt({
question: "👨⚖️ Please provide clarification about your contract terms:",
});
return { userClarification };
}This intervention exemplifies the validation-driven nature of HITL: The system only pauses to request human input when it has identified specific gaps that could compromise the quality of the analysis. As an improvement, in production systems, this node could be enhanced with validation logic to verify that all required information points are addressed before proceeding, ensuring the analysis is built on complete and accurate context.
generateFinalAnalysis: This node produces the final legal analysis by combining the selected precedent with the additional context provided by the user, if needed. Using the clarification gathered in the previous HITL step, the LLM synthesizes the precedent’s reasoning, the contract details supplied by the user, and the conditions that determine whether a breach may have occurred.
The node outputs a complete analysis that integrates legal interpretation and practical recommendations:
async function generateFinalAnalysis(state: typeof LegalResearchState.State) {
console.log("📋 Generating final legal analysis...\n");
const precedent = state.selectedPrecedent;
if (!precedent) return { finalAnalysis: "" };
const m = precedent.metadata;
const prompt = `
Original question: "${state.query}"
Selected precedent: ${m.title}
Outcome: ${m.outcome}
Reasoning: ${m.reasoning}
Lawyer's clarification: "${state.userClarification}"
Provide a comprehensive legal analysis integrating:
1. The selected precedent's reasoning
2. The lawyer's specific contract context
3. Conditions for breach vs. no breach
4. Practical recommendations
`;
const response = await llm.invoke([
{
role: "system",
content:
"You are a legal research assistant providing comprehensive analysis.",
},
{ role: "user", content: prompt },
]);
const finalAnalysis = response.content as string;
console.log(
"\n" +
"=".repeat(80) +
"\n" +
"⚖️ FINAL LEGAL ANALYSIS\n" +
"=".repeat(80) +
"\n\n" +
finalAnalysis +
"\n\n" +
"=".repeat(80) +
"\n"
);
return { finalAnalysis };
}Building graph:
const workflow = new StateGraph(LegalResearchState)
.addNode("searchPrecedents", searchPrecedents)
.addNode("precedentSelection", precedentSelection)
.addNode("selectPrecedent", selectPrecedent)
.addNode("validatePrecedentSelection", validatePrecedentSelection)
.addNode("processValidation", processValidation)
.addNode("createDraft", createDraft)
.addNode("requestClarification", requestClarification)
.addNode("generateFinalAnalysis", generateFinalAnalysis)
.addEdge("__start__", "searchPrecedents")
.addEdge("searchPrecedents", "precedentSelection") // HITL #1
.addEdge("precedentSelection", "selectPrecedent")
.addEdge("selectPrecedent", "validatePrecedentSelection") // Selection validation
.addEdge("validatePrecedentSelection", "processValidation")
.addConditionalEdges(
"processValidation",
(state: typeof LegalResearchState.State) => {
const userInput = (state.validation || "").toLowerCase().trim();
const isValid = userInput === "yes" || userInput === "y";
return isValid ? "validated" : "reselect";
},
{
validated: "createDraft",
reselect: "precedentSelection",
}
)
.addConditionalEdges(
"createDraft",
(state: typeof LegalResearchState.State) => {
// If ambiguity detected, request clarification (HITL #2)
if (state.ambiguityDetected) return "needsClarification";
// Otherwise, generate final analysis
return "final";
},
{
needsClarification: "requestClarification",
final: "generateFinalAnalysis",
}
)
.addEdge("requestClarification", "generateFinalAnalysis") // HITL #2
.addEdge("generateFinalAnalysis", "__end__");In the graph, we can see the createDraft conditional edge, which defines the condition for choosing the “final” path. As shown, the decision now depends on whether the draft analysis detected ambiguity that requires additional clarification.
Put all together to be executed:
await ingestData();
// Compile workflow
const app = workflow.compile({ checkpointer: new MemorySaver() });
const config = { configurable: { thread_id: "hitl-circular-thread" } };
await saveGraphImage(app);
// Execute workflow
const legalQuestion =
"Does a pattern of repeated delays constitute breach even if each individual delay is minor?";
console.log(`⚖️ LEGAL QUESTION: "${legalQuestion}"\n`);
let currentState = await app.invoke({ query: legalQuestion }, config);
// Handle all interruptions in a loop
while ((currentState as any).__interrupt__?.length > 0) {
console.log("\n💭 APPLICATION PAUSED WAITING FOR USER INPUT...");
const interruptQuestion = (currentState as any).__interrupt__[0]?.value
?.question;
// Handling empty responses
let userChoice = "";
while (!userChoice.trim()) {
userChoice = await getUserInput(interruptQuestion || "👤 YOUR CHOICE: ");
if (!userChoice.trim()) {
console.log("⚠️ Please provide a response.\n");
}
}
currentState = await app.invoke(
new Command({ resume: userChoice.trim() }),
config
);
}Execute the script
With all code allocated, let's execute the main.ts file, writing the following command on terminal:
tsx main.tsOnce the script is executed, the question “Does a pattern of repeated delays constitute breach even if each individual delay is minor?” will be sent to Elasticsearch to perform a proximity search, and the results retrieved from the index will be displayed. The app detects that multiple relevant precedents match the query, so it pauses execution and asks the user to help disambiguate which legal precedent is most applicable:
📚 Searching for relevant legal precedents with query:
Does a pattern of repeated delays constitute breach even if each individual delay is minor?
Found 5 relevant precedents:
1. Case H: Pattern of Repeated Delays (CASE-H-2021)
Type: ongoing service agreement
Outcome: breach found
Key reasoning: pattern demonstrated failure to perform, cumulative effect
Delay period: multiple instances
2. Case E: Minor Delay Quality Maintained (CASE-E-2022)
Type: service agreement
Outcome: minor breach only
Key reasoning: delay minimal, quality maintained, termination unjustified
Delay period: five days
3. Case A: Delay Breach with Operational Impact (CASE-A-2023)
Type: service agreement
Outcome: breach found
Key reasoning: delay affected operations and caused financial harm
Delay period: two weeks
4. Case B: Delay Without Explicit Schedule (CASE-B-2022)
Type: consulting agreement
Outcome: no breach found
Key reasoning: no explicit deadline defined, no demonstrable harm
Delay period: three weeks
5. Case C: Justified Delay External Factors (CASE-C-2023)
Type: construction service
Outcome: no breach found
Key reasoning: external factors beyond control, force majeure applied
Delay period: one month
⚖️ HITL #1: Human input needed
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Which precedent is most similar to your case?The interesting thing about this application is that we can use natural language to choose one option, letting the LLM interpret the user’s input to determine the correct choice. Let’s see what happens if we enter the text “Case H”:
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Which precedent is most similar to your case? Case H
✅ Selected: Case H: Pattern of Repeated DelaysAfter case selection, the application requests a small validation to confirm that the model selected the correct use case. If you answer “no”, the application returns to the case selection step:
Validation needed
Selected precedent: Case H: Pattern of Repeated Delays (CASE-H-2021)
Type: ongoing service agreement
Outcome: breach found
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Is this the correct precedent? (yes/no): yesOnce confirmed, the application workflow continues drafting the analysis:
✅ Precedent confirmed.
📝 Drafting initial legal analysis...
AMBIGUITY DETECTED:
Based on Case H, a pattern of repeated delays can indeed constitute a breach of contract, even if each individual delay is minor. The outcome in Case H indicates that the cumulative effect of these minor delays led to a significant failure to perform the contractual obligations adequately. The reasoning emphasizes that consistent performance is critical in fulfilling the terms of a contract. Therefore, if the repeated delays create a situation where the overall performance is hindered, this pattern could be interpreted as a breach. However, the interpretation may depend on the specific terms of the contract at issue, as well as the expectations of performance set forth in that contract.
Missing information:
1. Specific contract terms regarding performance timelines
2. Details on the individual delays (duration, frequency)
3. Context on consequences of delays stated in the contract
4. Other parties' expectations or agreements related to performance
⚖️ HITL #2: Additional context needed
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Please provide clarification about your contract terms:The model takes the user’s case selection and integrates it into the workflow, proceeding with the final analysis once enough context has been provided. In this step, the system also makes use of the previously detected ambiguity: The draft analysis highlighted missing contractual details that could meaningfully affect the legal interpretation. These “missing information” items guide the model in determining what clarifications are essential to resolve uncertainty before producing a reliable final opinion.
The user must include in the next input the requested clarifications. Let's try with "Contract requires ‘prompt delivery’ without timelines. 8 delays of 2-4 days over 6 months. $50K in losses from 3 missed client deadlines. Vendor notified but pattern continued.":
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Please provide clarification about your contract terms: Contract requires "prompt delivery" without timelines. 8 delays of 2-4 days over 6 months. $50K in losses from 3 missed client deadlines. Vendor notified but pattern continued.
📋 Generating final legal analysis...
================================================================================
⚖️ FINAL LEGAL ANALYSIS
================================================================================
To analyze the question of whether a pattern of repeated minor delays constitutes a breach of contract, we need to combine insights from the selected precedent, the specifics of the lawyer's contract situation, conditions that typically govern breach versus non-breach, and practical recommendations for the lawyer moving forward.
### 1. Selected Precedent's Reasoning
The precedent case, referred to as Case H, found that a pattern of repeated delays amounted to a breach of contract. The court reasoned that even minor individual delays, when considered cumulatively, demonstrated a failure to perform as stipulated in the contract. The underlying rationale was that the cumulative effect of these minor delays could significantly undermine the purpose of the contract, which typically aims for timely performance and reliable delivery.
### 2. Lawyer's Specific Contract Context
In the lawyer's situation, the contract specified "prompt delivery" but did not provide a strict timeline. The vendor experienced 8 delays ranging from 2 to 4 days over a period of 6 months. These delays culminated in $50,000 in losses due to three missed client deadlines. The vendor was notified regarding these delays; however, the pattern of delays persisted.
Key considerations include:
- **Nature of the Obligations**: While “prompt delivery” does not define a strict timeline, it does imply an expectation for timely performance.
- **Material Impact**: The missed client deadlines indicate that these delays had a material adverse effect on the lawyer's ability to fulfill contractual obligations to third parties, likely triggering damages.
### 3. Conditions for Breach vs. No Breach
**Conditions for Breach**:
- **Pattern and Cumulative Effect**: Similar to the reasoning in Case H, evidence of a habitual pattern of delays can amount to a breach. Even if individual delays are minor, when combined, they may show a lack of diligence or reliability by the vendor.
- **Materiality**: The impact of these delays is crucial. If the cumulative delays adversely affect the contract's purpose or cause significant losses, this reinforces the case for a breach.
- **Notification and Opportunity to Cure**: The fact that the vendor was notified of the delays and failed to rectify the behavior can often be interpreted as a further indication of breach.
**Conditions for No Breach**:
- **Non-Material Delays**: If the delays did not affect the overall contractual performance or client obligations, this may lessen the likelihood of establishing a breach. However, given the risks and losses involved, this seems less relevant in this scenario.
- **Force Majeure or Justifiable Delays**: If the vendor could show that these delays were due to justify circumstances not within their control, it may potentially provide a defense against breach claims.
### 4. Practical Recommendations
1. **Assess Damages**: Document the exact nature of the financial losses incurred due to the missed deadlines to substantiate claims of damages.
2. **Gather Evidence**: Collect all communication regarding the delays, including any notifications sent to the vendor about the issues.
3. **Consider Breach of Contract Action**: Based on the precedent and accumulated delays, consider formalized communication to the vendor regarding a breach of contract claim, highlighting both the pattern and the impact of these repeated delays.
4. **Evaluate Remedies**: Depending upon the contract specifics, the lawyer may wish to pursue several remedies, including:
- **Compensatory Damages**: For the financial losses due to missed deadlines.
- **Specific Performance**: If timely delivery is critical and can still be enforced.
- **Contract Termination**: Depending on the severity, terminating the contract and seeking replacements may be warranted.
5. **Negotiate Terms**: If continuing to work with the current vendor is strategic, the lawyer should consider renegotiating terms for performance guarantees or penalties for further delays.
6. **Future Contracts**: In future contracts, consider including explicit timelines and conditions for prompt delivery, as well as specified damages for delays to better safeguard against this issue.
By integrating the legal principles from the precedent with the specific context and conditions outlined, the lawyer can formulate a solid plan to address the repeated delays by the vendor effectively.This output shows the final stage of the workflow, where the model integrates the selected precedent (Case H) and the lawyer’s clarifications to generate a complete legal analysis. The system explains why the pattern of delays likely constitutes a breach, outlines the factors that support this interpretation, and provides practical recommendations. Overall, the output demonstrates how the HITL clarifications resolve ambiguity and allow the model to produce a well-founded, context-specific legal opinion.
Other real-world scenarios
This kind of application, using Elasticsearch, LangGraph, and HITL, can be useful in other kinds of apps, including:
- Reviewing tools calls before their execution; for example, in financial trading, a human approves buy/sell orders before they’re placed.
- Provide additional parameters when needed; for example, in customer support triage, where a human agent selects the correct issue category when the AI finds multiple possible interpretations of the customer’s problem.
And there are plenty of use cases to discover, where HITL will be a game changer.
Conclusion
With LangGraph and Elasticsearch, we can build agents that make their own decisions and act as linear workflows or follow conditional paths based on context. With human in the loop, the agents can involve the actual user in the decision-making process to fill contextual gaps and request confirmations on systems where fault tolerance is critical.
The key advantage of this approach is that you can filter a large dataset using Elasticsearch capabilities and then use an LLM to select a single document based on the user intent; that is, HITL. The LLM complements Elasticsearch by handling the dynamics of how users express their intent..
This approach keeps the system fast and token efficient, as we’re only sending the LLM what’s needed to make the final decision and not the whole dataset. And at the same time, this keeps it very precise at detecting user intent and iterating until the desired option is picked.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
May 26, 2026
Cutting agent costs with pre-computed context
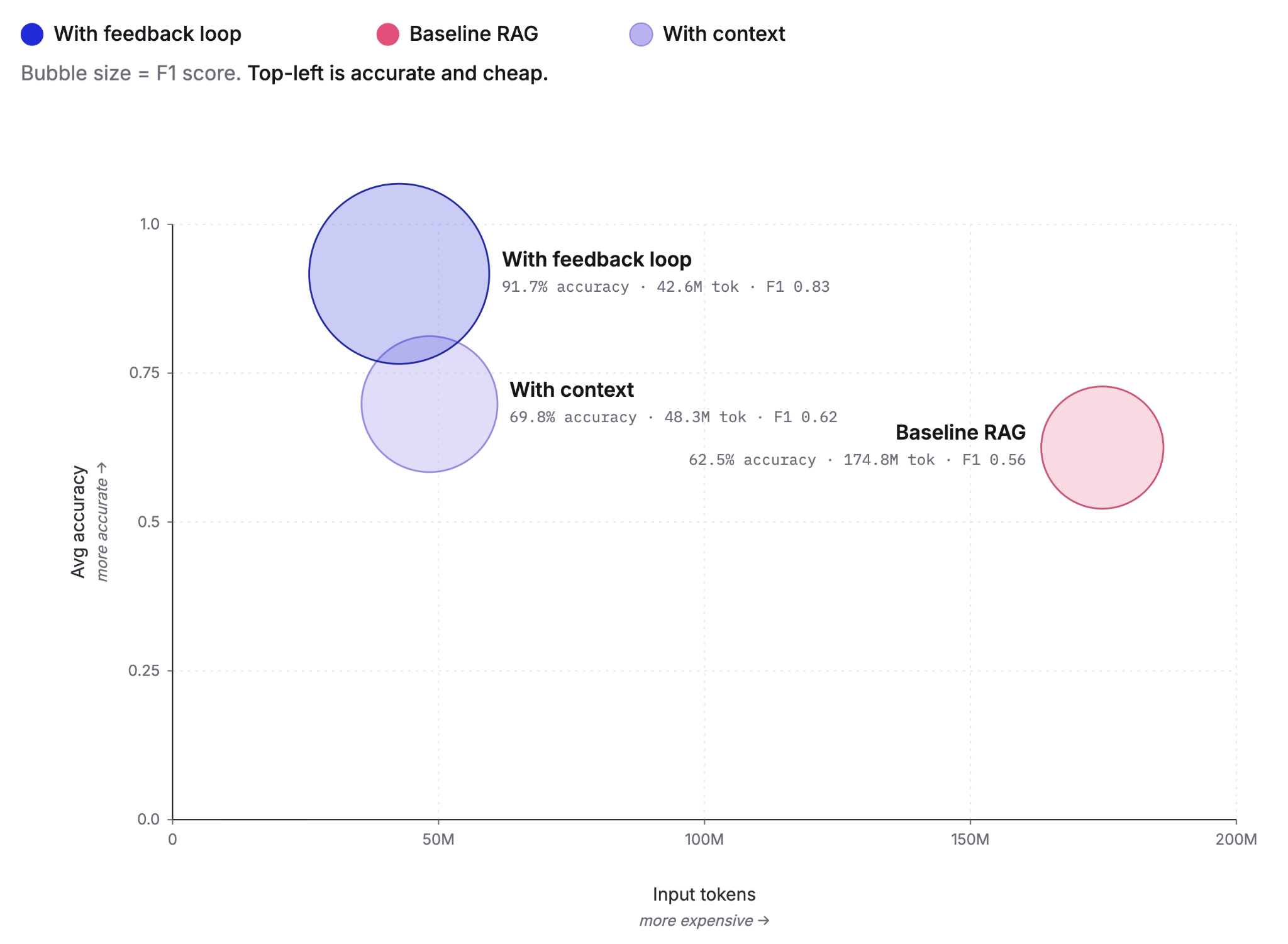
Pre-computing context as Knowledge Indicators reduces LLM agent token costs by up to 75% and improves answer accuracy from 60% to 92%. This post covers the extraction, retrieval and feedback loop that make it work, tested against the BrowseComp-Plus benchmark.
May 5, 2026
Elastic Agent Builder: How we taught AI agents to manage their own context
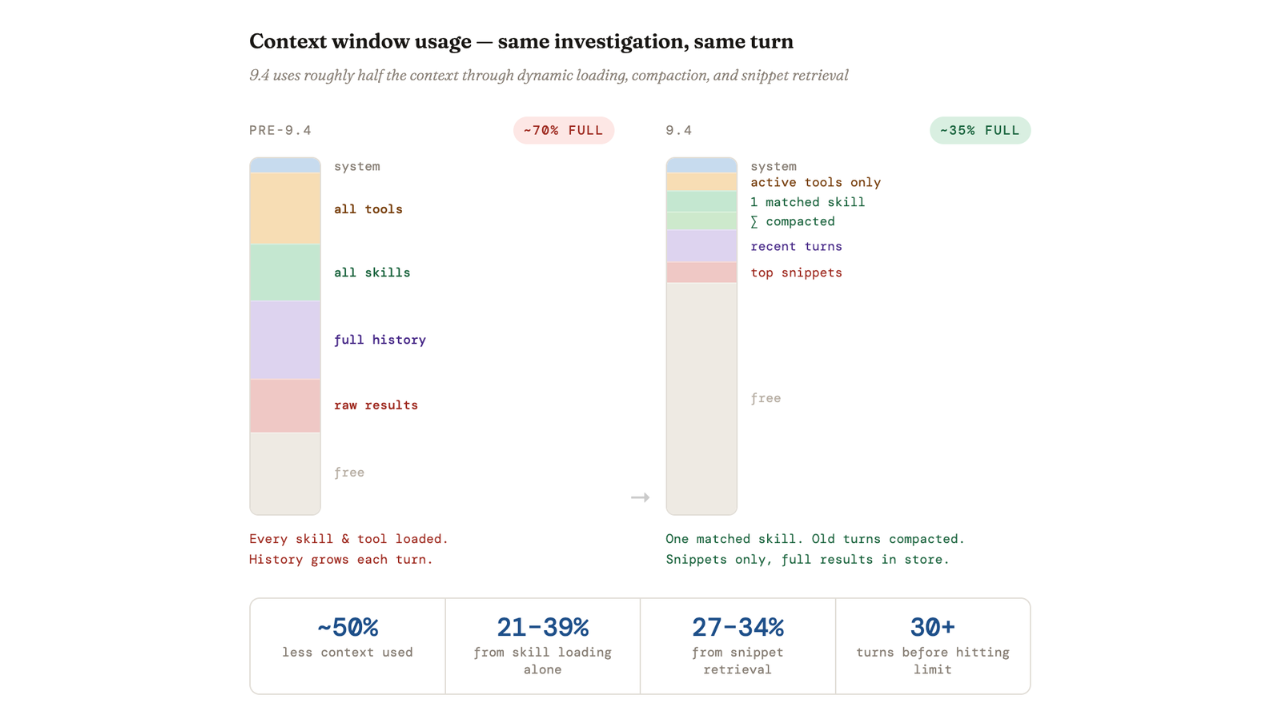
Agent Builder in Elasticsearch 9.4 ships dynamically loaded skills, a conversation context store, selective compaction, and external connectors to cut token costs by 40% and let agents handle their own context management.

April 29, 2026
Elastic-caveman: Cutting AI response tokens by 64% without losing the best of Elastic
Learn how to use elastic-caveman to cut AI response tokens while keeping the Elastic agentic brilliance.
April 8, 2026
How to build agentic AI applications with Mastra and Elasticsearch
Learn how to build agentic AI applications using Mastra and Elasticsearch through a practical example.

March 23, 2026
Using Elasticsearch Inference API along with Hugging Face models
Learn how to connect Elasticsearch to Hugging Face models using inference endpoints, and build a multilingual blog recommendation system with semantic search and chat completions.