In diesem Artikel werden wir untersuchen, wie LangGraph und Elasticsearch kombiniert werden können, um eine Human-in-the-Loop (HITL)-Anwendung zu erstellen. Dieser Ansatz ermöglicht es KI-Systemen, Nutzer direkt in den Entscheidungsprozess einzubeziehen, wodurch Interaktionen zuverlässiger und kontextsensitiver werden. Wir werden ein praktisches Beispiel mit einem kontextgesteuerten Szenario implementieren, um zu demonstrieren, wie LangGraph-Workflows mit Elasticsearch integriert werden können, um Daten abzurufen, Benutzereingaben zu verarbeiten und verfeinerte Ergebnisse zu liefern.
Voraussetzungen
- NodeJS Version 18 oder neuer
- OpenAI-API-Schlüssel
- Elasticsearch 8.x+ Deployment
Warum LangGraph für Produktions-HITL-Systeme verwenden
In einem früheren Artikel haben wir LangGraph und seine Vorteile für den Aufbau eines RAG-Systems mit LLMs sowie bedingten Kanten vorgestellt, um automatisch Entscheidungen zu treffen und Ergebnisse anzuzeigen. Manchmal möchten wir nicht, dass das System komplett autonom agiert, sondern dass die Nutzer innerhalb der Ausführungsschleife Optionen auswählen und Entscheidungen treffen. Dieses Konzept heißt Human in the Loop.
Human-in-the-loop oder in der Schleife
Dabei handelt es sich um ein KI-Konzept, das es einer realen Person ermöglicht, mit KI-Systemen zu interagieren, um mehr Kontext zu liefern, Reaktionen zu bewerten, Reaktionen zu bearbeiten, nach weiteren Informationen zu fragen usw. Dies ist in Szenarien mit niedriger Fehlertoleranz wie Compliance, Entscheidungsfindung oder Inhaltsgenerierung sehr nützlich und trägt zur Verbesserung der Zuverlässigkeit der LLM-Outputs bei.
Ein häufiges Beispiel ist, wenn Ihr Programmierassistent Sie um die Erlaubnis bittet, einen bestimmten Befehl am Terminal auszuführen, oder Ihnen den Schritt-für-Schritt-Denkprozess zeigt, den Sie genehmigen müssen, bevor Sie mit dem Programmieren beginnen.
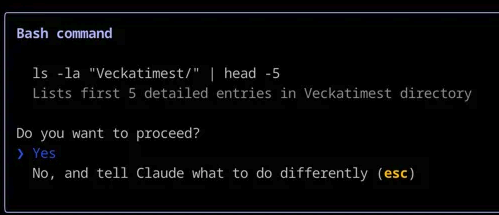
Claude Code verwendet Human-in-the-Loop, um Sie um Bestätigung zu bitten, bevor ein Bash-Befehl ausgeführt wird
Elasticsearch + LangGraph: Wie sie interagieren
LangChain ermöglicht uns die Verwendung von Elasticsearch als Vektorspeicher und die Durchführung von Abfragen innerhalb von LangGraph-Anwendungen, was nützlich ist, um Volltext- oder semantische Suchen auszuführen, während LangGraph verwendet wird, um den spezifischen Workflow, die Tools und die Interaktionen zu definieren. HITL wird außerdem als zusätzliche Interaktionsebene mit dem Nutzer hinzugefügt.
Praktische Umsetzung: Human-in-the-loop
Stellen wir uns einen Fall vor, in dem ein Anwalt eine Frage zu einem Fall hat, den er kürzlich übernommen hat. Ohne die richtigen Hilfsmittel müsste er juristische Artikel und Präzedenzfälle manuell suchen, sie vollständig lesen und dann interpretieren, wie sie auf seine Situation anwendbar sind. Mit LangGraph und Elasticsearch können wir jedoch ein System aufbauen, das eine Datenbank von Rechtspräzedenzfällen durchsucht und eine Fallanalyse erstellt, die die spezifischen Details und den Kontext des Anwalts einbezieht.
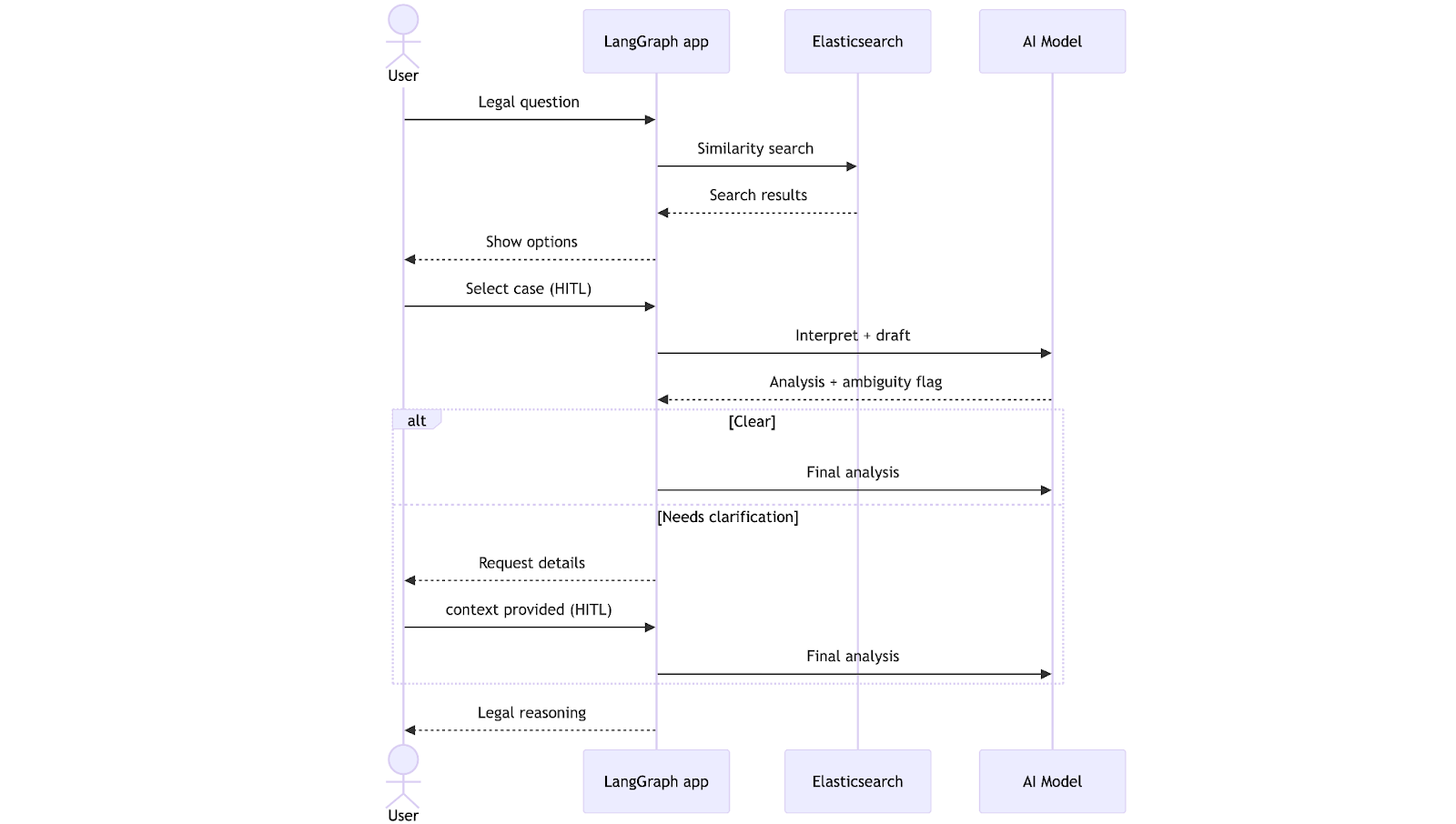
Der Workflow beginnt, wenn der Anwalt eine Rechtsfrage einreicht. Das System führt eine Vektorsuche in Elasticsearch durch, ruft die relevantesten Präzedenzfälle ab und präsentiert sie dem Anwalt zur Auswahl in natürlicher Sprache. Nach der Auswahl erstellt der LLM einen Analyseentwurf und prüft, ob die Informationen vollständig sind. An dieser Stelle kann der Workflow zwei Pfaden folgen: Wenn alles klar ist, wird direkt eine endgültige Analyse generiert; wenn nicht, pausiert er, um eine Klärung vom Anwalt anzufordern. Sobald der fehlende Kontext bereitgestellt wird, schließt das System die Analyse ab und gibt sie unter Berücksichtigung der Klärungen zurück.
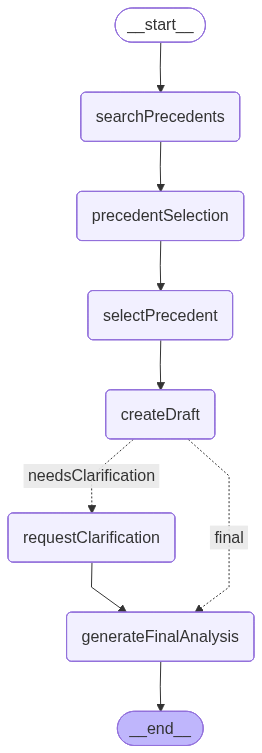
Nachfolgend ein von LangGraph erstellter Graph, der zeigt, wie die App am Ende der Entwicklung aussehen wird. Jeder Node repräsentiert ein Tool oder eine Funktionalität:
Datensatz
Hier ist der Datensatz, der für dieses Beispiel verwendet wird. Dieser Datensatz enthält eine Sammlung von Präzedenzfällen, die jeweils einen Fall mit Verzögerungen bei der Leistungserbringung, die Begründung des Gerichts und das Endergebnis beschreiben.
[
{
"pageContent": "Legal precedent: Case B - Service delay not considered breach. A consulting contract used term 'timely delivery' without specific dates. A three-week delay occurred but contract lacked explicit schedule. Court ruled no breach as parties had not defined concrete timeline and delay did not cause demonstrable harm.",
"metadata": {
"caseId": "CASE-B-2022",
"contractType": "consulting agreement",
"delayPeriod": "three weeks",
"outcome": "no breach found",
"reasoning": "no explicit deadline defined, no demonstrable harm",
"keyTerms": "timely delivery, open terms, schedule definition",
"title": "Case B: Delay Without Explicit Schedule"
}
},
...
]Einrichtung der Ingestion und des Indexes
Die Indexeinrichtung und die Logik zur Daten-Ingestion sind in der Datei dataIngestion.ts definiert, in der wir Funktionen deklarieren, die die Indexerstellung übernehmen. Dieses Setup ist kompatibel mit der LangChain Vektorspeicher-Schnittstelle für Elasticsearch.
Hinweis: Die Mapping-Konfiguration ist ebenfalls in der dataIngestion.ts Datei enthalten.
Pakete installieren und Umgebungsvariablen einrichten
Lassen Sie uns ein Node.js-Projekt mit den Standardeinstellungen initialisieren:
- @elastic/Elasticsearch: Elasticsearch-Client für Node.js. Wird verwendet, um Verbindungen herzustellen, Indizes zu erstellen und Abfragen auszuführen.
- @langchain/community: Bietet Integrationen für von der Community unterstützte Tools, einschließlich des ElasticVectorSearch-Stores.
- @langchain/core: Kernbausteine von LangChain, wie Ketten, Prompts und Hilfsmittel.
- @langchain/langgraph: Fügt graphbasierte Orchestrierung hinzu, die Workflows mit Knoten, Kanten und Zustandsverwaltung ermöglicht.
- @langchain/openai: Bietet Zugriff auf OpenAI-Modelle (LLMs und Einbettungen) über LangChain.
- dotenv: Lädt Umgebungsvariablen aus einer.env Datei in process.env.
- tsx: Ist ein nützliches Tool zum Ausführen von TypeScript-Code.
Führen Sie folgenden Befehl in der Konsole aus, um alle zu installieren:
npm install @elastic/elasticsearch @langchain/community @langchain/core @langchain/langgraph @langchain/openai dotenv --legacy-peer-deps && npm install --save-dev tsxErstellen Sie eine .env Datei, um die Umgebungsvariablen einzurichten:
ELASTICSEARCH_ENDPOINT=
ELASTICSEARCH_API_KEY=
OPENAI_API_KEY=Wir werden TypeScript zum Schreiben des Codes verwenden, da es eine Ebene der Typsicherheit und eine bessere Entwicklererfahrung bietet. Erstellen Sie eine TypeScript-Datei mit dem Namen main.ts und fügen Sie den Code des nächsten Abschnitts ein.
Pakete importieren
In der Datei main.ts importieren wir zunächst die benötigten Module und initialisieren die Umgebungsvariablenkonfiguration. Dazu gehören die Kernkomponenten von LangGraph, die OpenAI-Modellintegrationen und der Elasticsearch-Client.
Wir importieren außerdem Folgendes aus der dataIngestion.ts-Datei :
- ingestData: eine Funktion, die den Index erstellt und die Daten aufnimmt.
- Dokument und Dokumentmetadaten: Schnittstellen, die die Dokumentstruktur des Datensatzes definieren.
Elasticsearch Vector Store Client, Embeddings Client und OpenAI-Client
Dieser Code initialisiert den Vektorspeicher, den Embeddings-Client und einen OpenAI-Client.
const VECTOR_INDEX = "legal-precedents";
const llm = new ChatOpenAI({ model: "gpt-4o-mini" });
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
});
const esClient = new Client({
node: process.env.ELASTICSEARCH_ENDPOINT,
auth: {
apiKey: process.env.ELASTICSEARCH_API_KEY ?? "",
},
});
const vectorStore = new ElasticVectorSearch(embeddings, {
client: esClient,
indexName: VECTOR_INDEX,
});Das Workflow-Statusschema der Anwendung hilft bei der Kommunikation zwischen den Nodes:
const LegalResearchState = Annotation.Root({
query: Annotation<string>(),
analyzedConcepts: Annotation<string[]>(),
precedents: Annotation<Document[]>(),
selectedPrecedent: Annotation<Document | null>(),
draftAnalysis: Annotation<string>(),
ambiguityDetected: Annotation<boolean>(),
userClarification: Annotation<string>(),
finalAnalysis: Annotation<string>(),
});Im Zustandsobjekt geben wir durch die Nodes die Nutzeranfrage, die daraus extrahierten Konzepte, die abgerufenen Rechtspräzedenzfälle und etwaige Mehrdeutigkeiten durch. Der Zustand verfolgt auch den vom Nutzer ausgewählten Präzedenzfall, die während des Prozesses erstellte Entwurfsanalyse und die endgültige Analyse, sobald alle Klärungen abgeschlossen sind.
Knoten
searchPrecedents: Dieser Node führt eine Ähnlichkeitssuche im Elasticsearch-Vektorspeicher basierend auf dem Eingang des Nutzers durch. Er ruft bis zu 5 übereinstimmende Dokumente ab und druckt sie aus, damit der Nutzer sie einsehen kann.
async function searchPrecedents(state: typeof LegalResearchState.State) {
console.log(
"📚 Searching for relevant legal precedents with query:\n",
state.query
);
const results = await vectorStore.similaritySearch(state.query, 5);
const precedents = results.map((d) => d as Document);
console.log(`Found ${precedents.length} relevant precedents:\n`);
for (let i = 0; i < precedents.length; i++) {
const p = precedents[i];
const m = p.metadata;
console.log(
`${i + 1}. ${m.title} (${m.caseId})\n` +
` Type: ${m.contractType}\n` +
` Outcome: ${m.outcome}\n` +
` Key reasoning: ${m.reasoning}\n` +
` Delay period: ${m.delayPeriod}\n`
);
}
return { precedents };
}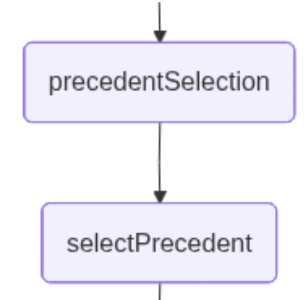
Präzedenzfallauswahl: Dieser Node ermöglicht es dem Nutzer, mithilfe natürlicher Sprache denjenigen Anwendungsfall auszuwählen, der durch die Proximity-Suche ermittelt wurde und am besten zur Frage passt. An diesem Punkt unterbricht die Anwendung den Workflow und wartet auf die Nutzereingabe.
function precedentSelection(state: typeof LegalResearchState.State) {
console.log("\n⚖️ HITL #1: Human input needed\n");
const question = "👨⚖️ Which precedent is most similar to your case? ";
const userChoice = interrupt({ question });
return { userChoice };
}selectPrecedent: Dieser Node sendet den Nutzerinput zusammen mit den abgerufenen Dokumenten zur Interpretation, sodass eines von ihnen ausgewählt werden kann. Das LLM erfüllt diese Aufgabe, indem es eine Zahl zurückgibt, die das Dokument repräsentiert, das es aus der natürlichen Spracheingabe des Nutzers ableitet.
async function selectPrecedent(state: typeof LegalResearchState.State) {
const precedents = state.precedents || [];
const userInput = (state as any).userChoice || "";
const precedentsList = precedents
.map((p, i) => {
const m = p.metadata;
return `${i + 1}. ${m.caseId}: ${m.title} - ${m.outcome}`;
})
.join("\n");
const structuredLlm = llm.withStructuredOutput({
name: "precedent_selection",
schema: {
type: "object",
properties: {
selected_number: {
type: "number",
description:
"The precedent number selected by the lawyer (1-based index)",
minimum: 1,
maximum: precedents.length,
},
},
required: ["selected_number"],
},
});
const prompt = `
The lawyer said: "${userInput}"
Available precedents:
${precedentsList}
Which precedent number (1-${precedents.length}) matches their selection?
`;
const response = await structuredLlm.invoke([
{
role: "system",
content:
"You are an assistant that interprets lawyer's selection and returns the corresponding precedent number.",
},
{ role: "user", content: prompt },
]);
const selectedIndex = response.selected_number - 1;
const selectedPrecedent = precedents[selectedIndex] || precedents[0];
console.log(`✅ Selected: ${selectedPrecedent.metadata.title}\n`);
return { selectedPrecedent };
}
createDraft: Dieser Node generiert die erste rechtliche Analyse basierend auf dem vom Nutzer gewählten Präzedenzfall. Er verwendet einen LLM, um zu beurteilen, inwieweit der gewählte Präzedenzfall auf die Frage des Anwalts anwendbar ist, und um festzustellen, ob dem System genügend Informationen vorliegen, um fortzufahren.
Wenn der Präzedenzfall direkt angewendet werden kann, erstellt der Node einen Analyseentwurf und nimmt den richtigen Pfad zum End-Node. Wenn das LLM Unklarheiten wie undefinierte Vertragsbedingungen, fehlende Zeitrahmendetails oder unklare Bedingungen erkennt, gibt es eine Markierung zurück, die darauf hinweist, dass eine Klärung erforderlich ist, zusammen mit einer Liste der spezifischen Informationen, die bereitgestellt werden müssen. In diesem Fall löst die Mehrdeutigkeit den linken Pfad des Graphen aus.
async function createDraft(state: typeof LegalResearchState.State) {
console.log("📝 Drafting initial legal analysis...\n");
const precedent = state.selectedPrecedent;
if (!precedent) return { draftAnalysis: "" };
const m = precedent.metadata;
const structuredLlm = llm.withStructuredOutput({
name: "draft_analysis",
schema: {
type: "object",
properties: {
needs_clarification: {
type: "boolean",
description:
"Whether the analysis requires clarification about contract terms or context",
},
analysis_text: {
type: "string",
description: "The draft legal analysis or the ambiguity explanation",
},
missing_information: {
type: "array",
items: { type: "string" },
description:
"List of specific information needed if clarification is required (empty if no clarification needed)",
},
},
required: ["needs_clarification", "analysis_text", "missing_information"],
},
});
const prompt = `
Based on this precedent:
Case: ${m.title}
Outcome: ${m.outcome}
Reasoning: ${m.reasoning}
Key terms: ${m.keyTerms}
And the lawyer's question: "${state.query}"
Draft a legal analysis applying this precedent to the question.
If you need more context about the specific contract terms, timeline details,
or other critical information to provide accurate analysis, set needs_clarification
to true and list what information is missing.
Otherwise, provide the legal analysis directly.
`;
const response = await structuredLlm.invoke([
{
role: "system",
content:
"You are a legal research assistant that analyzes cases and identifies when additional context is needed.",
},
{ role: "user", content: prompt },
]);
let displayText: string;
if (response.needs_clarification) {
const missingInfoList = response.missing_information
.map((info: string, i: number) => `${i + 1}. ${info}`)
.join("\n");
displayText = `AMBIGUITY DETECTED:\n${response.analysis_text}\n\nMissing information:\n${missingInfoList}`;
} else {
displayText = `ANALYSIS:\n${response.analysis_text}`;
}
console.log(displayText + "\n");
return {
draftAnalysis: displayText,
ambiguityDetected: response.needs_clarification,
};
}Die beiden möglichen Pfade des Graphen sehen folgendermaßen aus:
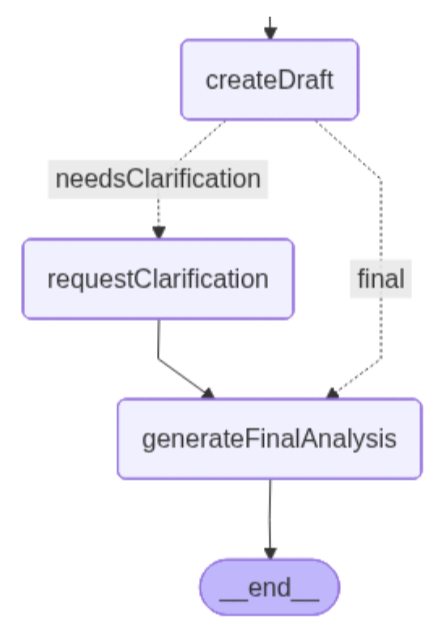
Der linke Pfad enthält einen zusätzlichen Node, der die Klarstellung übernimmt.
RequestClarification: Dieser Node löst den zweiten Human-in-the-Loop-Schritt aus, wenn das System feststellt, dass dem Analyseentwurf grundlegender Kontext fehlt. Der Workflow wird unterbrochen und der Nutzer wird aufgefordert, die fehlenden Vertragsdetails zu klären, die der vorherige Node entdeckt hat.
function requestClarification(state: typeof LegalResearchState.State) {
console.log("\n⚖️ HITL #2: Additional context needed\n");
const userClarification = interrupt({
question: "👨⚖️ Please provide clarification about your contract terms:",
});
return { userClarification };
}generateFinalAnalysis: Dieser Node erstellt die endgültige rechtliche Analyse, indem er den ausgewählten Präzedenzfall mit dem vom Nutzer bereitgestellten zusätzlichen Kontext kombiniert, falls nötig. Anhand der im vorherigen HITL-Schritt gesammelten Klarstellung fasst das LLM die Begründung des Präzedenzfalls, die vom Nutzer bereitgestellten Vertragsdetails und die Bedingungen zusammen, die bestimmen, ob ein Verstoß stattgefunden haben könnte.
Der Node liefert eine vollständige Analyse, die rechtliche Auslegung und praktische Empfehlungen integriert.
async function generateFinalAnalysis(state: typeof LegalResearchState.State) {
console.log("📋 Generating final legal analysis...\n");
const precedent = state.selectedPrecedent;
if (!precedent) return { finalAnalysis: "" };
const m = precedent.metadata;
const prompt = `
Original question: "${state.query}"
Selected precedent: ${m.title}
Outcome: ${m.outcome}
Reasoning: ${m.reasoning}
Lawyer's clarification: "${state.userClarification}"
Provide a comprehensive legal analysis integrating:
1. The selected precedent's reasoning
2. The lawyer's specific contract context
3. Conditions for breach vs. no breach
4. Practical recommendations
`;
const response = await llm.invoke([
{
role: "system",
content:
"You are a legal research assistant providing comprehensive analysis.",
},
{ role: "user", content: prompt },
]);
const finalAnalysis = response.content as string;
console.log(
"\n" +
"=".repeat(80) +
"\n" +
"⚖️ FINAL LEGAL ANALYSIS\n" +
"=".repeat(80) +
"\n\n" +
finalAnalysis +
"\n\n" +
"=".repeat(80) +
"\n"
);
return { finalAnalysis };
}Graph erstellen:
const workflow = new StateGraph(LegalResearchState)
.addNode("analyzeQuery", analyzeQuery)
.addNode("searchPrecedents", searchPrecedents)
.addNode("precedentSelection", precedentSelection)
.addNode("selectPrecedent", selectPrecedent)
.addNode("createDraft", createDraft)
.addNode("requestClarification", requestClarification)
.addNode("generateFinalAnalysis", generateFinalAnalysis)
.addEdge("__start__", "analyzeQuery")
.addEdge("analyzeQuery", "searchPrecedents")
.addEdge("searchPrecedents", "precedentSelection") // HITL #1
.addEdge("precedentSelection", "selectPrecedent")
.addEdge("selectPrecedent", "createDraft")
.addConditionalEdges(
"createDraft",
(state: typeof LegalResearchState.State) => {
// If ambiguity detected, request clarification (HITL #2)
if (state.ambiguityDetected) return "needsClarification";
// Otherwise, generate final analysis
return "final";
},
{
needsClarification: "requestClarification",
final: "generateFinalAnalysis",
}
)
.addEdge("requestClarification", "generateFinalAnalysis") // HITL #2
.addEdge("generateFinalAnalysis", "__end__");Im Graph können wir sehen, dass die bedingte Kante die Bedingung für die Wahl des „finalen“ Pfades definiert. Wie gezeigt, hängt die Entscheidung nun davon ab, ob der Analyseentwurf Unklarheiten aufgedeckt hat, die einer weiteren Klärung bedürfen.
Zusammengefasst zur Ausführung:
await ingestData();
// Compile workflow
const app = workflow.compile({ checkpointer: new MemorySaver() });
const config = { configurable: { thread_id: "hitl-circular-thread" } };
await saveGraphImage(app);
// Execute workflow
const legalQuestion =
"Does a pattern of repeated delays constitute breach even if each individual delay is minor?";
console.log(`⚖️ LEGAL QUESTION: "${legalQuestion}"\n`);
let currentState = await app.invoke({ query: legalQuestion }, config);
// Handle all interruptions in a loop
while ((currentState as any).__interrupt__?.length > 0) {
console.log("\n💭 APPLICATION PAUSED WAITING FOR USER INPUT...");
const interruptQuestion = (currentState as any).__interrupt__[0]?.value
?.question;
const userChoice = await getUserInput(
interruptQuestion || "👤 YOUR CHOICE: "
);
currentState = await app.invoke(
new Command({ resume: userChoice }),
config
);
}Führen Sie das Skript aus:
Nachdem wir den gesamten Code zugewiesen haben, führen wir die Datei main.ts aus, indem wir den folgenden Befehl im Terminal eingeben:
tsx main.tsSobald das Skript ausgeführt wird, wird die Frage „Stellt ein Muster wiederholter Verzögerungen einen Verstoß dar, selbst wenn jede einzelne Verzögerung geringfügig ist?“ an Elasticsearch gesendet, um eine Proximity-Suche durchzuführen, und die aus dem Index abgerufenen Ergebnisse werden angezeigt. Die App erkennt, dass mehrere relevante Präzedenzfälle mit der Abfrage übereinstimmen, pausiert die Ausführung und bittet den Nutzer, bei der Klarstellung zu helfen, welcher rechtliche Präzedenzfall am relevantesten ist:
📚 Searching for relevant legal precedents with query:
Does a pattern of repeated delays constitute breach even if each individual delay is minor?
Found 5 relevant precedents:
1. Case H: Pattern of Repeated Delays (CASE-H-2021)
Type: ongoing service agreement
Outcome: breach found
Key reasoning: pattern demonstrated failure to perform, cumulative effect
Delay period: multiple instances
2. Case E: Minor Delay Quality Maintained (CASE-E-2022)
Type: service agreement
Outcome: minor breach only
Key reasoning: delay minimal, quality maintained, termination unjustified
Delay period: five days
3. Case A: Delay Breach with Operational Impact (CASE-A-2023)
Type: service agreement
Outcome: breach found
Key reasoning: delay affected operations and caused financial harm
Delay period: two weeks
4. Case B: Delay Without Explicit Schedule (CASE-B-2022)
Type: consulting agreement
Outcome: no breach found
Key reasoning: no explicit deadline defined, no demonstrable harm
Delay period: three weeks
5. Case C: Justified Delay External Factors (CASE-C-2023)
Type: construction service
Outcome: no breach found
Key reasoning: external factors beyond control, force majeure applied
Delay period: one month
⚖️ HITL #1: Human input needed
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Which precedent is most similar to your case?Das Interessante an dieser Anwendung ist, dass wir in natürlicher Sprache eine Option auswählen können, wobei das LLM den Input des Nutzers interpretiert, um die richtige Wahl zu ermitteln. Lassen Sie uns sehen, was passiert, wenn wir den Text eingeben: „Fall H“
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Which precedent is most similar to your case? Case H
✅ Selected: Case H: Pattern of Repeated Delays
📝 Drafting initial legal analysis...
AMBIGUITY DETECTED:
Based on Case H, a pattern of repeated delays can indeed constitute a breach of contract, even if each individual delay is minor. The outcome in Case H indicates that the cumulative effect of these minor delays led to a significant failure to perform the contractual obligations adequately. The reasoning emphasizes that consistent performance is critical in fulfilling the terms of a contract. Therefore, if the repeated delays create a situation where the overall performance is hindered, this pattern could be interpreted as a breach. However, the interpretation may depend on the specific terms of the contract at issue, as well as the expectations of performance set forth in that contract.
Missing information:
1. Specific contract terms regarding performance timelines
2. Details on the individual delays (duration, frequency)
3. Context on consequences of delays stated in the contract
4. Other parties' expectations or agreements related to performance
⚖️ HITL #2: Additional context needed
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Please provide clarification about your contract terms:Das Modell nimmt die Erläuterungen des Nutzers auf und integriert sie in den Workflow, um mit der endgültigen Analyse fortzufahren, sobald genügend Kontext vorhanden ist. In diesem Schritt nutzt das System auch die zuvor festgestellte Unklarheit: Die Entwurfsanalyse hat fehlende Vertragsdetails hervorgehoben, die die rechtliche Auslegung maßgeblich beeinflussen könnten. Diese „fehlenden Informationen“ dienen dem Modell als Leitfaden, um festzustellen, welche Klarstellungen unerlässlich sind, um Unsicherheiten zu beseitigen, bevor eine verlässliche endgültige Meinung abgegeben werden kann.
Der Nutzer muss bei dem nächsten Input die gewünschten Erläuterungen angeben. Versuchen wir es mit „Vertrag erfordert 'pünktliche Lieferung' ohne Zeitpläne. 8 Verzögerungen von 2-4 Tagen über 6 Monate. 50.000 $ Verluste durch 3 verpasste Kundenfristen. Verkäufer benachrichtigt, aber das Muster hält an.“
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Please provide clarification about your contract terms: Contract requires "prompt delivery" without timelines. 8 delays of 2-4 days over 6 months. $50K in losses from 3 missed client deadlines. Vendor notified but pattern continued.
📋 Generating final legal analysis...
================================================================================
⚖️ FINAL LEGAL ANALYSIS
================================================================================
To analyze the question of whether a pattern of repeated minor delays constitutes a breach of contract, we need to combine insights from the selected precedent, the specifics of the lawyer's contract situation, conditions that typically govern breach versus non-breach, and practical recommendations for the lawyer moving forward.
### 1. Selected Precedent's Reasoning
The precedent case, referred to as Case H, found that a pattern of repeated delays amounted to a breach of contract. The court reasoned that even minor individual delays, when considered cumulatively, demonstrated a failure to perform as stipulated in the contract. The underlying rationale was that the cumulative effect of these minor delays could significantly undermine the purpose of the contract, which typically aims for timely performance and reliable delivery.
### 2. Lawyer's Specific Contract Context
In the lawyer's situation, the contract specified "prompt delivery" but did not provide a strict timeline. The vendor experienced 8 delays ranging from 2 to 4 days over a period of 6 months. These delays culminated in $50,000 in losses due to three missed client deadlines. The vendor was notified regarding these delays; however, the pattern of delays persisted.
Key considerations include:
- **Nature of the Obligations**: While “prompt delivery” does not define a strict timeline, it does imply an expectation for timely performance.
- **Material Impact**: The missed client deadlines indicate that these delays had a material adverse effect on the lawyer's ability to fulfill contractual obligations to third parties, likely triggering damages.
### 3. Conditions for Breach vs. No Breach
**Conditions for Breach**:
- **Pattern and Cumulative Effect**: Similar to the reasoning in Case H, evidence of a habitual pattern of delays can amount to a breach. Even if individual delays are minor, when combined, they may show a lack of diligence or reliability by the vendor.
- **Materiality**: The impact of these delays is crucial. If the cumulative delays adversely affect the contract's purpose or cause significant losses, this reinforces the case for a breach.
- **Notification and Opportunity to Cure**: The fact that the vendor was notified of the delays and failed to rectify the behavior can often be interpreted as a further indication of breach.
**Conditions for No Breach**:
- **Non-Material Delays**: If the delays did not affect the overall contractual performance or client obligations, this may lessen the likelihood of establishing a breach. However, given the risks and losses involved, this seems less relevant in this scenario.
- **Force Majeure or Justifiable Delays**: If the vendor could show that these delays were due to justify circumstances not within their control, it may potentially provide a defense against breach claims.
### 4. Practical Recommendations
1. **Assess Damages**: Document the exact nature of the financial losses incurred due to the missed deadlines to substantiate claims of damages.
2. **Gather Evidence**: Collect all communication regarding the delays, including any notifications sent to the vendor about the issues.
3. **Consider Breach of Contract Action**: Based on the precedent and accumulated delays, consider formalized communication to the vendor regarding a breach of contract claim, highlighting both the pattern and the impact of these repeated delays.
4. **Evaluate Remedies**: Depending upon the contract specifics, the lawyer may wish to pursue several remedies, including:
- **Compensatory Damages**: For the financial losses due to missed deadlines.
- **Specific Performance**: If timely delivery is critical and can still be enforced.
- **Contract Termination**: Depending on the severity, terminating the contract and seeking replacements may be warranted.
5. **Negotiate Terms**: If continuing to work with the current vendor is strategic, the lawyer should consider renegotiating terms for performance guarantees or penalties for further delays.
6. **Future Contracts**: In future contracts, consider including explicit timelines and conditions for prompt delivery, as well as specified damages for delays to better safeguard against this issue.
By integrating the legal principles from the precedent with the specific context and conditions outlined, the lawyer can formulate a solid plan to address the repeated delays by the vendor effectively.Dieser Ausgang zeigt die letzte Phase des Workflows, in der das Modell den ausgewählte Präzedenzfall (Fall H) und die Klärungen des Anwalts integriert, um eine vollständige rechtliche Analyse zu generieren. Das System erklärt, warum das Muster der Verzögerungen wahrscheinlich einen Verstoß darstellt, skizziert die Faktoren, die diese Interpretation stützen, und gibt praktische Empfehlungen. Insgesamt zeigt der Output, wie die HITL-Klärungen Mehrdeutigkeiten auflösen und es dem Modell ermöglichen, eine fundierte, kontextspezifische rechtliche Stellungnahme zu erstellen.
Andere reale Szenarien
Diese Art von Anwendung, die Elasticsearch, LangGraph und Human-in-the-Loop verwendet, kann in anderen Apps nützlich sein wie:
- Bei der Überprüfung von Tool-Aufrufen vor ihrer Ausführung, zum Beispiel im Finanzhandel, genehmigt ein Mensch Kauf-/Verkaufsaufträge, bevor sie erteilt werden.
- Fügen Sie bei Bedarf zusätzliche Parameter an, zum Beispiel bei der Triage des Kundensupports, bei der ein menschlicher Mitarbeiter die richtige Problemkategorie auswählt, wenn die KI mehrere mögliche Interpretationen des Problems des Kunden findet.
Und es gibt viele Anwendungsfälle, die es noch zu entdecken gilt, in denen Human-in-the-Loop ein entscheidender Faktor sein wird.
Fazit
Mit LangGraph und Elasticsearch können wir Agenten erstellen, die eigene Entscheidungen treffen und als lineare Workflows agieren oder Bedingungen erfüllen, die sie dazu veranlassen, den einen oder anderen Pfad zu wählen. Mit Human-in-the-Loop können die Agenten den tatsächlichen Nutzer in den Entscheidungsprozess einbeziehen, um kontextuelle Lücken zu füllen und Bestätigungen für Systeme anzufordern, bei denen Fehlertoleranz entscheidend ist.
Einer der Vorteile dieses Ansatzes ist, dass man einen großen Datensatz mithilfe der Elasticsearch-Funktionen filtern und dann mit einem LLM ein einzelnes Dokument als Nutzerauswahl erhalten kann. Dieser letzte Schritt wäre mit Elasticsearch allein viel komplizierter, da es viele Möglichkeiten gibt, wie ein Mensch ein Ergebnis in natürlicher Sprache interpretieren kann.
Mit diesem Ansatz bleibt das System schnell und Token-effizient, da wir dem LLM nur das senden, was für die endgültige Entscheidung benötigt wird, und nicht die gesamten Datensätze. Gleichzeitig wird die Absicht des Nutzers sehr genau erkannt und so lange iteriert, bis die gewünschte Option ausgewählt ist.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
April 8, 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.
March 25, 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

March 23, 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.
March 27, 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.
March 17, 2026
Die Gemini CLI-Erweiterung für Elasticsearch mit Tools und Fähigkeiten
Wir stellen die Erweiterung von Elastic für Googles Gemini CLI vor, mit der Elasticsearch-Daten in Entwickler- und agentischen Workflows gesucht, abgerufen und analysiert werden können.